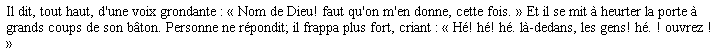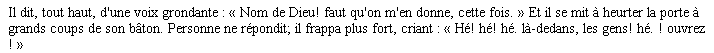L'autonomisation : une voie raisonnable pour la maîtrise des ressources d'Internet
Russon Wooldridge
University of Toronto
Communication présentée dans le cadre du 2ème colloque international « Les études françaises valorisées
par les nouvelles technologies d'information et de communication » : littérature - internet - bibliothèque (Lisieux, 27-28 mai 2002).
© 2002 R. Wooldridge
Introduction
1. Requêtes générales et requêtes ciblées, sites répertoires et moteurs de recherche
1.1. Quelques sites répertoires de ressources (à titre d'exemples)
1.2. Deux sites sur Montaigne
1.3. Quelques sites textes
1.4. +Montaigne +vanité à travers deux moteurs de recherche (documents en français)
1.5. Conclusion : déficience des outils face au quantitatif et au changeant
2. Facteurs qui nuisent au sérieux d'un site
2.1. Polices de caractères
2.2. Largeur de l'écran et justification à droite
2.3. Largeur de l'écran et espaces mous
2.4. La couleur
2.5. Les cadres
2.6. La saisie optique
2.7. Navigabilité du site et le principe "index.html"
2.8. Conclusion : le manque de métier de la cybertypographie
Introduction
Dans le résumé, nous avions dit : "Les conditions de la documentation et de la recherche ont changé radicalement avec l'avènement du World Wide Web. Répertorier exhaustivement les ressources imprimées pour un domaine donné était un objectif raisonnable dans la mesure où un objet publié sur papier, diffusé par un éditeur et catalogué en bibliothèque avait une existence stable. Tenter de le faire pour des ressources en ligne relève de l'illusoire car aucun document publié sur Internet ne comporte la garantie d'une existence durable : les ressources du WWW ne peuvent théoriquement être recensées qu'à un moment donné et n'ont de valeur qu'éphémère, celle d'une synchronie absolue. Tout répertoire de ressources en ligne à prétention exhaustive et à caractère stable ne peut être que partiel et défectueux, puisqu'il contient fatalement des informations obsolètes. Mieux vaut alors donner à l'usager des outils critiques et analytiques lui permettant de faire lui-même ses propres inventaires ciblés ponctuels."
Déclaration de principe que nous voudrions un tout petit peu nuancer dans la première partie de la présente communication, en parlant des richesses et des limitations des outils généralistes et des outils thématiques. Dans la deuxième partie, nous examinerons quelques facteurs qui nuisent au sérieux d'un site et qui relèvent essentiellement de la manière dont un site est construit. (L'essentiel de ce qui suit dérive de différentes études publiées en ligne dans la rubrique ACRE "pour une Autonomisation de la critique de ressources en ligne" du Net des Études françaises.)
1. Requêtes générales et requêtes ciblées, sites répertoires et moteurs de recherche
Dans cette partie, nous voulons tester sommairement quelques sites consacrés aux Études françaises, à un auteur particulier ou aux textes littéraires. Soit les thèmes: "Littérature française du XVIe siècle / Montaigne" (requêtes générales), "la vanité chez Montaigne" (requête ciblée).
1.1. Quelques sites répertoires de ressources (à titre d'exemples)
| Site
| Littérature du XVIe
| Montaigne
| Montaigne + vanité
|
| 1. "ClicNet, un site culturel et littéraire francophone" (Swarthmore College, Pennsylvania)
| Non
| -> Texte des Essais (Trismégiste)
| Non
|
| 2. "University at Albany Libraries: French and Francophone Studies" (New York)
| Non
| -> Montaigne Studies
| Non
|
| 3. "HAPAX: French Resources on the Web" (Sweet Briar College, Virginia)
| Non
| Non
| Non
|
| 4. "Tennessee Bob's Famous French Links" (University of Tennessee at Martin)
| -> "Early Modern French Literature" (qui donne beaucoup de liens vers des sites sur le XVIe et 14 sites sur Montaigne)
| Non
| Non
|
1.2. Deux sites sur Montaigne
Nota. Site n° 1: pour trouver le traitement du thème de la vanité, il faut demander "back issues", puis parcourir la table des matières de chaque volume. Site n° 2: chemin = Publications de la S.I.A.M. -> parcourir la table des matières de chaque numéro.
1.3. Quelques sites textes
| Site
| Essais de Montaigne
| Format
|
| 1. ARTFL (U. of Chicago)
| Éd. de 1965 conforme à l'éd. de 1580
| Base de données
|
| 2. ATHENA (U. de Genève)
| a) -> Gallica; b) -> Trismégiste (éd. de 1595)
| a) Mode image (pdf); b) Mode plein texte (html)
|
| 3. GALLICA (Bibliothèque nationale de France)
| Plusieurs éditions, dont 1580 et 1595
| Mode image (pdf)
|
1.4. +Montaigne +vanité à travers deux moteurs de recherche (documents en français)
Nous retenons quatre documents clés:
Nota 1: a) le mémoire de Hurlburt (n° 3) n'est pas indexé par Google; b) l'adresse donnée par AltaVista en sept. 2001 pour le Bulletin de la Société des Amis de Montaigne (n° 4) ne fonctionne plus en avril 2002 ("Not Found").
Nota 2: a) les Montaigne Studies (cf. 1.2) signalent dans leurs "renaissance links" le site de Trismégiste (n° 1) mais le lien est faux; elles renvoient à la Bibliothèque de Bordeaux (cf. n° 2), comme aussi à la Société Internationale des Amis de Montaigne (n° 4); elles ne signalent pas le mémoire de Hurlburt (n° 3), pourtant sur un autre serveur de l'université de Chicago. b) le site de la Société Internationale des Amis de Montaigne (cf. 1.2) renvoie aux Essais chez Trimégiste et aux Montaigne Studies, mais ne signale ni la Bibliothèque de Bordeaux, ni le mémoire de Hurlburt.
1.5. Conclusion : déficience des outils face au quantitatif et au changeant
Un outil généraliste comme les moteurs de recherche AltaVista ou Google trouve la plupart des sites importants sur un sujet donné (sujet général ou sujet pointu), mais pas tous : on remarquera, par exemple, que le mémoire de Hurlburt (cf. 1.4, n° 3) n'est pas indexé par Google. Un outil thématique comme les sites répertoires donne toujours des pistes, mais pas nécessairement celles qu'on souhaite y trouver ; dans les limites étroites de la présente démonstration, le site le plus riche est Early Modern French Literature (cf. 1.1), qui est en fait un sous-site de Tennessee Bob's Famous French Links (1.1, n° 4) ; un des défauts inévitables des sites répertoires est la présence de liens morts (cf. 1.4, note 2a) ; aucun des sites explorés ne mentione le mémoire de Hurlburt. Celui-ci est donc très difficile à trouver, encore plus à découvrir : à ce sujet, on notera que le champ 'meta name="subject"' du mémoire ne donne comme contenu que "DEA"; le 'meta name="Generator"' révèle le contenu "Microsoft Word 97/98"; le titre html est "PartIvoyage.doc" !. Il y aurait beaucoup à dire sur l'utilisation de mauvais outils dans la création de documents html; nous allons en dire un peu dans la deuxième partie.
2. Facteurs qui nuisent au sérieux d'un site
2.1. Polices de caractères
Le lecteur est habitué à lire un texte littéraire composé dans un caractère romain à sérif. Si on lui donne le choix de caractère (option du navigateur), il peut toujours sélectionner un caractère sans sérif ou autre. Le caractère des documents suivants est déterminé à l'avance :
a) <FONT FACE="Genava,verdana,geneva,arial" SIZE=2>
b) <font face="Arial">
On notera que dans le deuxième exemple tout le texte est mis en relief, source de fatigue et d'agacement supplémentaire.
2.2. Largeur de l'écran et justification à droite
La justification de la marge droite est traditionnelle depuis les débuts de l'imprimerie et avant. Le scribe ou l'imprimeur connaissait la largeur de la page (fixe) et s'aidait d'abréviations conventionnelles ou d'incises typographiques. Les logiciels de traitement de texte pratiquent également la justification de la marge droite, la définition de la largeur de la ligne et l'incise en fin de ligne. Conçus uniquement pour verser un résultat sur papier, ils sont inadéquats pour produire un document html. Et pourtant c'est ce qu'ils font ; de plus, le logiciel de production de documents html le plus utilisé est le traitement de texte Word, qui... justifie la marge droite (<p align="justify">). Celle-ci ne fonctionne pas sur écran de la même façon que sur papier : la largeur de la ligne (celle de l'écran) est variable, comme aussi la taille des caractères (possibilité chez l'usager d'agrandir ou de réduire), l'incise typographique n'existe plus. Voici ce que cela peut donner :
2.3. Largeur de l'écran et espaces mous
Le même traitement de texte sait gérer l'espace dur (généralement avant ":", ";", "?", "!" et "»" et après "«"). Dans une conversion html, l'espace dur tantôt est maintenu (en html " " = "non-breaking space"), tantôt, et très souvent, devient un espace mou, avec des résultats potentiellement laids. Selon la largeur de l'écran, cela peut donner, par exemple :
ou bien :
2.4. La couleur
Le lecteur est habitué à lire un texte littéraire imprimé en noir sur un fond plus ou moins blanc. Le texte suivant peut lui être désagréable :
La couleur du texte est définie <font color="#400000">, le fond <body background="../p1.jpg"> et, en plus, tout le texte est en gras (<strong> ... </strong>).
2.5. Les cadres
L'abus de l'utilisation des cadres ("frames") peut aboutir à plusieurs types d'effets désagrébles, dont voici quelques-uns, tous hélas ! courants sur le WWW.
a) bandeau décoratif vertical superflu et agaçant :
b) bandeau fonctionnel vertical (menu) distrayant, avec perte de la marge gauche dans la plage lecture :
c) appropriation déloyale du site d'autrui (l'adresse "URL" ne change pas) :
2.6. La saisie optique
Les fautes d'orthographe de la composition typographique sont linguistiques et humaines (ex. font au lieu de fond) ; celles de la saisie optique sont visuelles et mécaniques ("ISSO" pour "I550"). Un exemple qui ne gêne pas l'oeil, mais cache le mot à la fonction mécanique "Recherche" :
Le mot "Instruction" de la première ligne est en fait "lnstruction", avec un "l" minuscule. La fonction "Recherche" ne trouvera donc pas le mot instruction.
2.7. Navigabilité du site et le principe "index.html"
Beaucoup de pages WWW n'ont pas de boutons de navigation permettant d'aller à la page principale du document, de la rubrique ou du site ("Home"). Une des raisons du manque de boutons est la conception de la page comme figurant dans un cadre "contenu" associé à un cadre "menu" (cf. 2.5) ; une recherche par moteur de recherche trouve ces pages et les affiche isolément. Un des principes du WWW, connu à ses débuts mais très peu aujourd'hui, est celui d'une page "index.html" ou "nom-de-répertoire.html", placée dans tout répertoire, servant de page de défaut de celui-ci et fonctionnant comme page principale des documents du répertoire. En retranchant à l'adresse URL le nom du fichier, l'usager devrait pouvoir retrouver la page principale du document ou de la rubrique. Ainsi, à partir de l'adresse
http://humanities.uchicago.edu/orgs/montaigne/renlinks.html, on devrait pouvoir retrouver la page d'accueil des Montaigne Studies au moyen de l'adresse http://humanities.uchicago.edu/orgs/montaigne/, ce qui s'avère être le cas. Les très nombreuses exceptions à cette règle sont essentiellement de deux types (les exemples donnés sont des pages sans boutons) :
a) manque de structure du site :
http://lang.haverford.edu/faculty/dsedley/guestbook/montaigne.htm = page sur "Montaigne [...]
Votre commentaire"
http://lang.haverford.edu/faculty/dsedley/guestbook/ = "Index of /faculty/dsedley/guestbook"
http://lang.haverford.edu/faculty/dsedley/ = "Index of /faculty/dsedley"
http://lang.haverford.edu/faculty/ = "Index of /faculty"
http://lang.haverford.edu/ = "The home page for the Mellon Language Project has been moved to....
http://lang.swarthmore.edu/mellon/".
Autrement dit, aucun des répertoires, à l'exception de la racine, n'a de page de défaut. L'adresse de base parle de tout autre chose.
b) dirigisme
http://www.snes.edu/~adapt/echanges/francais/lycee/sepulveda.html = page sur "ETUDE D'UNE
OEUVRE INTÉGRALE" avec mention bibliographique de "Darcos...- Essai sur la vanité (III9)"
http://www.snes.edu/~adapt/echanges/francais/lycee/ = "Forbidden"
http://www.snes.edu/~adapt/echanges/francais/ = "Forbidden"
http://www.snes.edu/~adapt/echanges/ = "Forbidden"
http://www.snes.edu/~adapt/ = "[Adapt éditions: livres sur et pour l'école, test de cédroms, liens pour enseigner, bourse d'échange]"
L'usager n'a aucun moyen de naviguer le site, à part ce qui lui est offert sur une page d'accueil hiérarchiquement lointaine.
2.8. Conclusion : le manque de métier de la cybertypographie
La typographie classique est un métier séculaire héritier des pratiques du codex manuscrit, avec ses mise en page et mise en ligne fixes. Le nouveau médium du livre électronique cherche encore ses formes, dont certaines sont fixes (format image des documents pdf conçus souvent pour l'impression sur papier), mais dont la plupart sont dynamiques (format html). La grande majorité des cybertypographes – n'importe qui peut publier son propre "livre" en ligne, sans l'intervention éditoriale et typographique de la publication traditionnelle – n'ont pas de métier et se contentent souvent d'outils inadéquats pré-installés sur leur l'ordinateur. La liberté d'expression a donc son prix. La prise en compte par l'usager critique de la mise en forme des documents publiés en ligne peut conduire à ternir l'image d'un site autrement réputé "sérieux".
R. Wooldridge ,
University of Toronto
Toronto, 30 avril 2002
Retour au programme