FRE 272Y5
The Structure of Modern French: An Introduction
Premier trimestre
Notes de la semaine 12
(Présentation du contenu de L&B, ch. 18)
Révision de la dérivation et de la composition : exercices donnés à la fin des notes de la semaine 11
1. Analysez les dérivés sécurisation, officiellement, dizaines, revécu, jeunesse, inhabituelle, villageois, simplifiées, allégées.
• sécurisation (pas dans le texte) = dérivation nominale par suffixation (suffixe -ation) du verbe sécuriser (cf. sous-titre), lui-même dérivé par suffixation (suffixe -iser) du nom sécurité (cf. titre).
• officiellement adverbe dérivé par suffixation (-ment) du féminin de l'adjectif officiel (lui-même dérivé adjectival du nom office)
• dizaines dérivé nominal par suffixation (-aine) de l'adjectif numéral dix.
• revécu dérivé verbal par préfixation réitérative (re-) du verbe vivre.
• jeunesse dérivé nominal par suffixation (-esse) de l'adjectif jeune.
• inhabituelle dérivé adjectival par préfixation privative (in-) de l'adjectif habituel.
• villageois dérivation nominal (qui fonctionne aussi comme adjectif) par suffixation (-ois) du nom village
• simplifiées dérivé verbal par suffixation (-ifier) de l'adjectif simple.
• allégées dérivé verbal par préfixation (a-) et suffixation (-er) de l'adjectif léger – cf. alourdir, amoindrir, abêtir, abrutir, etc.
2. Le mot monogamie (cf. polygamie) est-ce un dérivé ou un composé? Quel est le sens de chaque élément?
• Monogamie et polygamie ont été composé en grec et sont arrivés en français au XVI s. en passant par le latin ecclésiastique (latin d'église) ; ils sont restés très rares en français jusqu'au XVIIIe et XIXe s. lorsqu'ils ont été repris d'abord en sociologie (phénomène social) puis en botanique et zoologie (phénomène naturel).
• Cependant les éléments mono- (= "un") et poly- (= "plusieurs") sont devenus des préfixes très productifs en français donnant des dérivés comme monochromatique, monographie, monolingue, monologue, monoparental (ex. famille monoparentale), monorail, monosyllabique, polycopier, polyester, polymorphe, polysémie, polysyllabique, polytechnique, polyvalent, etc.
3. Trouvez dans le texte des termes, comme mariage civil (voir le titre), qui seraient des mots composés (ou groupes figés) dans le contexte de la société civile.
• papiers d'identité (sous-titre) ; union civile (premier paragraphe) ; mariage coutumier (ibid.) ; papiers d'état-civil (3e para.) ; démarches administratives (ibid.) ; livret de famille (ibid.). On peut se demander si l'expression recherches d'emploi est à considérer comme une locution figée ou semi-figée.
• On notera aussi le nom de l'association "Promo-Femmes", combinaison par composition de promo-, forme tronquée de promotion, et de femmes (cf. le site web www.promo-web.org).
4. Dans le document "Trois couleurs: listes de mots", quelle sorte de liste est la liste A, quelle sorte de liste est la liste B?
• La liste A est extraite de la liste globale des mots de texte classés par ordre alphabétique.
• La liste B est extraite de la liste globale des mots de texte classés par ordre alphabétique inverse (alphabétisation à partir de la fin des mots et non à partir du début).
5. Trouvez dans les listes des mots préfixés et des mots suffixés regroupés.
• Mots préfixés en in- : immigrant < migrant (in- est un préfixe signifiant entrée ou contact dans l'espace) imposée < poser (in- est le même préfixe que dans le mot immigrant) ; inachevé (in- privatif + achever), indépendante (ibid. + dépendant) ; insu (ibid. + savoir).
• Mots préfixés en re- : rapporte (+ apporter) ; refaire (+ faire) ; regagne (+ gagner) ; repli (+ pli) ; reprend (+ prendre) ; retraite (la dérivation médiévale re- + traire (= mod. "tirer") est devenue opaque en français moderne) ; revoir (+ voir).
• Noms suffixés en -(i)té ("qualité") : égalité (égal +) ; humanité (humain +) ; fraternité (dérivé latin : frater + -itas) ; liberté (libre +) – en fait, tous les quatre sont des dérivés latins.
• Adverbes en -ment : rapidement (rapide +) ; follement (adjectif féminin folle +).
Les structures du lexique
Le lexique a beaucoup de structures différentes. Nous allons en examiner les principales. (À noter que les notes suivantes et le chapitre 18 du manuel divergent beaucoup, bien que le manuel donne des exemples utiles sur quelques points.)
1. Morphologie lexicale. Le lexique comprend des unités inanalysables (unités simples) et des unités analysables (unités complexes). Les dérivés et les composés, lorsque le processus de dérivation ou de composition reste transparent* (les composants gardent leur identité en français moderne), sont facilement analysables : dénationalisation se prête à une analyse en dé- (préfixe privatif), -nation- (racine lexicale au sens de "communauté sociale ou politique"), -al (suffixe adjectival au sens de "qui relève de"), -is (suffixe verbal au sens de "donner le caractère X à"), -ation (suffixe nominal au sens de "résultat de (ce processus)"). Nous avons étudié (semaine 11) les procédés d'abrégement par troncation, ellipse et siglaison.
* La transparence s'oppose à l'opacité : par exemple, la compostion du mot dorénavant (< d'orès en avant – en français moderne le mot maintenant a remplacé l'ancien ores ou orès) est opaque en français moderne et le mot fonctionne aujourd'hui comme un mot simple.
2. Origine et évolution des mots. Les mots gardent des traces graphiques ou/et phonétiques de leur provenance (cf. L&B, pp. 167-170). Un mot ayant subi une évolution phonétique dans son voyage depuis le latin jusqu'au français moderne en passant par le gallo-roman (du haut Moyen-Âge), l'ancien français (du Moyen-Âge) et le moyen français (de la Renaissance) aura perdu des consonnes en route et aura des voyelles transformées par rapport à l'étymon (l'étymon est le mot d'origine étrangère qui a donné lieu au mot indigène en question) : ainsi, le mot (ou étymon) latin fragilis est devenu par voie d'évolution phonétique frêle en français moderne. Le lexique se compose essentiellement de deux sortes de mots : les mots ayant subi depuis les débuts de la langue une évolution phonétique (les origines du français sont essentiellement le latin et le gaulois, langue celtique) et les emprunts. Les emprunts sont typiquement marqués : au XIVe siècle le français érudit a emprunté le mot fragile (au sens de "de peu d'importance") directement au latin fragilis. Ce genre de couple – frêle / fragile – s'appelle un doublet dont une des formes est populaire (frêle) et l'autre savante (fragile). Voici d'autres exemples de mots empruntés ayant gardé une trace de leur origine : yacht garde sa forme écrite néerlandaise (jacht) mais se prononce à l'anglaise et conformément au système de base français /j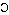 t/ ; redingote a subi des modifications de forme écrite et orale par rapport à l'étymon anglais riding-coat ; de méme, le mot bifteck issu de l'anglais beefsteak. Un emprunt récent : l'adjectif people (cf. la presse people = "celebrity press") garde sa graphie anglaise et plus ou moins sa prononciation d'origine. Le dérivé nominal désignant le processus de transformation du contenu original en contenu iconique superficiel (l'image remplaçant les idées) s'est d'abord écrit (printemps 2006) peopleisation (radical anglais + suffixes verbal et nominal français) mais s'écrit maintenant (automne 2006) pipolisation, conformément à la prononciation et aux règles orthographiques françaises. Un exemple d'un mot voyageur allant d'une langue à l'autre (il y en a d'autres) est le mot bacon, d'abord français prononcé /bak
t/ ; redingote a subi des modifications de forme écrite et orale par rapport à l'étymon anglais riding-coat ; de méme, le mot bifteck issu de l'anglais beefsteak. Un emprunt récent : l'adjectif people (cf. la presse people = "celebrity press") garde sa graphie anglaise et plus ou moins sa prononciation d'origine. Le dérivé nominal désignant le processus de transformation du contenu original en contenu iconique superficiel (l'image remplaçant les idées) s'est d'abord écrit (printemps 2006) peopleisation (radical anglais + suffixes verbal et nominal français) mais s'écrit maintenant (automne 2006) pipolisation, conformément à la prononciation et aux règles orthographiques françaises. Un exemple d'un mot voyageur allant d'une langue à l'autre (il y en a d'autres) est le mot bacon, d'abord français prononcé /bak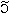 / au sens de "morceau de porc", puis emprunté par l'ancien anglais et prononcé /beik
/ au sens de "morceau de porc", puis emprunté par l'ancien anglais et prononcé /beik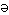 n/, devenu en anglais moderne "lard fumé vendu en tranches fines", et ensuite réemprunté par le français moderne au même sens et prononcé soit à l'anglaise, soit comme en ancien français. (L'exemple de fleureter => flirt, donné par L&B (p. 171), a été rejeté par les étymologistes.)
n/, devenu en anglais moderne "lard fumé vendu en tranches fines", et ensuite réemprunté par le français moderne au même sens et prononcé soit à l'anglaise, soit comme en ancien français. (L'exemple de fleureter => flirt, donné par L&B (p. 171), a été rejeté par les étymologistes.)
3. La création de mots. À la base du français se trouvent ce qu'on appelle les mots de souche ayant subi une évolution phonétique pendant leur passage depuis le latin jusqu'au français ; ex. fragilis => frêle. Comme procédés d'enrichissement de ce lexique de souche, on peut dire que les deux types de création de mots les plus fréquents sont a) l'emprunt (ex. fragilis => fragile, beefsteak => bifteck, Internet => Internet) et b) la dérivation et la composition (cf. ci-dessus et notes de la semaine 11). À ceux-là il faut ajouter : l'abrégement par troncation, ellipse ou siglaison (cf. notes de la semaine 11) ; le calque (emprunt du sens avec traduction du signifiant ; ex. angl. skateboard => fr. planche à roulettes, angl. email => fr. courriel).
(Le calque sémantique (emprunt d'un sens nouveau ajouté à un mot existant ; ex. angl. to realize "se rendre compte" => fr. réaliser normalement "rendre réel" + sens de l'anglais) est donné par le manuel comme procédé de création lexicale. En fait, il s'agit moins de la création d'un mot nouveau que d'une extension de sens d'un mot existant, ce qui se produit pour beaucoup de mots en dehors de toute influence étrangère. Cela intéresse davantage la sémantique lexicale que ce qu'on peut étudier en lexicologie dans le contexte réduit du cours FRE 272.)
4. Les familles et champs du lexique
À l'intérieur du lexique il y a toutes sortes de sous-domaines, dont les familles de mots et les champs sémantiques. Nous ne retiendrons dans le contexte de cette partie du cours FRE 272 que les familles lexicales. Une famille lexicale comprend, pour une synchronie donnée, tous les mots de même origine étymologique partageant un même sens global et fonctionnant entre eux selon les règles de la dérivation. À cet égard, on peut reprendre comme exemple typique la famille dont le chef de file est le mot nation et dont les autres membres de la famille sont national, nationaliser, nationalisation, dénationaliser, dénationalisation, auxquels il convient d'ajouter nationalisable, nationalisme, nationaliste, nationalité.
On doit comprendre dans la notion de famille lexicale les mots qui fonctionnent en français moderne comme dérivés, bien que leur forme diffère un peu synchroniquement de la forme du chef de famille mais partage avec lui la même étymologie. Cela permet de former des familles comme sourd, sourdement, assourdir (tous trois issus du latin surdus) et surdité (issu du latin surditas dérivé de surdus) ; ou chauve (du lat. calvus) et calvitie (du lat. calvities dérivé de calvus). Ou encore, pour reprendre l'exemple de la figure donnée ci-dessous, rompre et interrompre (lat. rumpere) plus rupture et interruption (lat. rumptum, forme flexionnelle de rumpere).
(Dans le domaine de la linguistique historique, il est intéressant d'étudier les familles étymologiques. Une famille étymologique contient, sur l'axe diachronique, tous les mots de même origine étymologique ; pour reprendre l'exemple de la figure reproduite ci-dessous, constituent une famille étymologique les étymons latins rumpere (angl. "to break") et rumptum (angl. "broken") et les mots français roture et roturier (au temps de la féodalité), puis rupture, interruption, rompre et interrompre (en français moderne). Dans le domaine de la sémantique, un champ sémantique contient tous les mots, quelle qu'en soit l'origine étymologique, partageant un même sens général : les mots signifiant "break" (dont rompre, briser, casser, etc.), les mots désignant la couleur ou l'intelligence ou les types de sièges, etc., etc.)
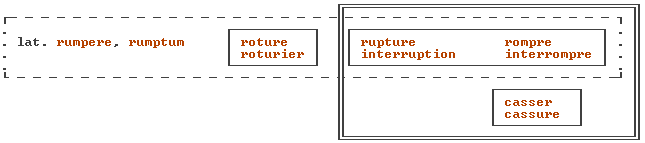
|
_ _ _ famille étymologique
_____ famille lexicale
===== champ sémantique
|
|
Figure adaptée du Robert Méthodique, Dictionnaires Robert, 1982, note méthodologique
|
|
5. Le lexique du point de vue synchronique.
C'est cet aspect qui nous intéresse le plus dans le cours FRE 272. Le critère de base de la structuration du lexique est la fréquence. On peut figurer le lexique comme une aire circulaire avec la langue courante ou générale au centre et, plus on s'éloigne du centre, des zones progressivement moins courantes et de plus en plus restreintes par la technicité, les domaines d'usage, la rareté dans le temps ou l'espace.
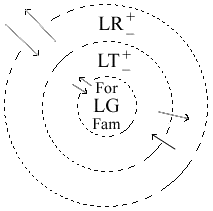
|
| Légende
LG = lexique général (dont le lexique courant)
For / Fam = les registres formel et familier de la langue générale
LT = lexique plus ou moins technique
LR = lexique plus ou moins rare
Flèches = le mouvement perpétuel des unités lexicales qui vont vers le centre ou s'en éloignent
|
Au centre se trouvent les mots les plus fréquents, les mots outils nécessaires pour construire toute phrase : de, à, le, la, les, est, ce, etc. Ensuite les mots outils commencent à être concurrencés, du point de vue de la fréquence, par les mots lexicaux les plus généraux : personne, chose, vie, monde, homme, femme, temps, etc. Tous les jours nous avons besoin de manger et de boire : manger, boire, eau, pain, etc. Ce besoin est structuré par les repas : déjeuner, dîner, plat, assiette, verre, etc. Tout le monde mange et boit, mais seulement certaines personnes préparent les repas : cuire, farine, beurre, mélanger, préparer, recette, etc. Les personnes qui préparent les choses à manger et à boire peuvent être des spécialistes : boulanger, boucher, traiteur, cuisinier, etc. Ces spécialistes distinguent entre différents types de beurre ou de farine : beurre salé, beurre sans sel, farine de blé, farine de seigle, etc. Et on pourrait continuer le chemin du très général au très particulier, du lexique le plus fréquent au lexique le moins fréquent.
6. Les dictionnaires et les grands corpus
Cette idée simpliste du lexique, qui est virtuel et relève de la langue (ou le code), permet de comprendre ce que les dictionnaires (qui sont des tentatives de description du lexique) mettent dans leurs pages. Un dictionnaire d'apprentissage ne répertoriera que les mots jugés courants, alors qu'un dictionnaire dit général, comme Le Petit Robert, essayera de faire un inventaire de tous les mots de la langue générale et les mots techniques ou autrement "marginaux" jugés les plus importants. Le Petit Robert est édité en un volume et sert à tout le monde ; on l'achète pour soi-même ou on l'offre en cadeau. Il y a aussi des dictionnaires plus extensifs en plusieurs volumes, que l'on trouve sur les étagères de la bibliothèque ; par exemple, le Trésor de la langue française en 16 volumes, publié entre 1971 et 1994, composé sur la base d'un corpus de textes littéraires (surtout) et techniques (moins) des XIXe et XXe siècles (1789-1960). Le TLF a connu une informatisation, le TLFI (I = informatisé), que l'on peut consulter en ligne gratuitement à l'adresse <atilf.atilf.fr/tlf.htm>.
Un dictionnaire monolingue comme Le Petit Robert contient des informations donnant une bonne idée du degré d'importance des mots du lexique. En règle générale, plus un article (= angl. dictionary entry) est long, plus le mot est important, c'est-à-dire fréquent ; plus il est long, plus il contient de sens ou d'emplois différents du mot. Les mots à plusieurs sens sont des mots polysémiques, alors que les mots à un seul sens sont monosémiques (ce sont des mots techniques ou rares). Plus les mots sont polysémiques, plus ils sont importants.
Les gens qui font des dictionnaires s'appellent des lexicographes. Dans le passé, c'est essentiellement la compétence du lexicographe qui a fourni l'inventaire des mots à mettre dans son dictionnaire ; on a aussi tenu compte de ce qu'on avait mis dans les dictionnaires antérieurs. Aujourd'hui les bons dictionnaires sont fondés sur le dépouillement (analyse) de corpus, vastes ensembles de textes écrits ou/et oraux. Une branche très importante de la linguistique est la linguistique de corpus. Pour le français peu de choses se sont faites dans cette voie. Une enquête menée vers la fin des années 1950 a livré un corpus de conversations permettant d'élaborer un inventaire des mots les plus utilisés dans le français parlé et a donné lieu à un Dictionnaire du français fondamental contenant environ 3 000 mots (cf. Gougenheim 1958 dans la bibliographie de L&B). Pour voir des projets modernes concernant la constitution de très grands corpus de textes oraux et écrits, il faut regarder du côté de l'anglais. Un des grands projets les plus importants est le British National Corpus, que l'on peut consulter à l'adresse <www.natcorp.ox.ac.uk/> : "The British National Corpus (BNC) is a 100 million word collection of samples of written and spoken language from a wide range of sources, designed to represent a wide cross-section of current British English, both spoken and written." Ce corpus, qui réside à l'Université d'Oxford, est utilisé pour la mise à jour du prestigieux Oxford English Dictionary (OED).
(Pour celles et ceux qui voudront en savoir plus sur la linguistique de corpus, voir l'article "Corpus linguistics" de Wikipedia.)
7. Lexique et vocabulaire.
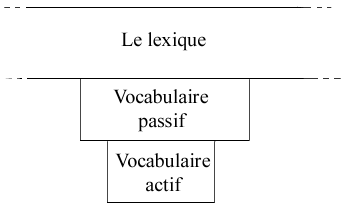
L'étendue du lexique est vaste et indéfinissable. C'est en principe l'ensemble des unités lexicales d'une langue donnée. Le sujet parlant possède une partie du lexique de sa langue. La compétence linguistique du sujet parlant est ce qu'on appelle un idiolecte ("parler individuel"), composé de compétences particulières phonologique, morphologique, syntaxique, sémantique, sociolinguistique et lexicale. La partie lexicale d'un idiolecte s'appelle un vocabulaire, qu'il faut distinguer en vocabulaire passif et vocabulaire actif. Le vocabulaire passif est l'ensemble des unités lexicales que le sujet parlant comprend (compétence passive), alors que le vocabulaire actif est l'ensemble des unités lexicales qu'il utilise (compétence active). Le vocabulaire passif est toujours plus grand que le vocabulaire actif, ce qui peut être représenté de la façon suivante :
8. Le vocabulaire des actes de parole
Au niveau du lexique (et du dictionnaire), il n'y a pas de "thèmes" ou de "sujets". Le British National Corpus essaie, par la très grande taille de son corpus (100 millions de mots), de neutraliser la spécificité de chacun des nombreux textes qui le composent. En revanche, au niveau des actes de parole, autrement dit des textes oraux ou écrits qui utilisent les potentialités de la compétence linguistique pour produire des performances – monologues, conversations, débats, lettres, pièces de théâtre, romans, etc. –, le vocabulaire utilisé est déterminé par deux facteurs : la fréquence et la disponibilité. Les mots outils, indispensables, sont toujours présents ; ce sont les mots lexicaux qui varient selon le sujet ou thème traité : thème d'une interprétation cinématographique de la France (Trois couleurs), thème du mariage (Mariage civil), thème des prétensions sociales (Le bourgeois gentilhomme de Molière), thème de la structure de la langue française (cours FRE 272), etc. Chaque situation de prise de parole fait donc appel au vocabulaire disponible pour traiter de tel ou tel thème (ou sujet).
Il y a deux façons d'appréhender la structure du vocabulaire d'un texte : par la lecture linéaire (ou horizontale), qui est celle de la lecture normale depuis le début jusqu'à la fin et qui rend une appréhension partielle fondée sur des impressions et des souvenirs incomplets ; et par une lecture verticale du texte, qui est celle rendue possible par l'ordinateur lorsqu'on veut étudier tel ou tel mot, telle ou telle liste de mots et qui donne accès à tout le texte. Quand on lit (lecture linéaire) le roman Bonheur d'occasion (en anglais, The Tin Flute) de Gabrielle Roy, on est conscient de plusieurs thèmes, dont la vie dans un quartier pauvre de Montréal, les rêves de bonheur de la jeune Florentine, les déceptions de la vie dure de sa mère, la maladie de son jeune frère. Pour Florentine, le seul vrai bonheur qu'elle a connu ce sont les expéditions à la campagne durant sa première jeunesse quand elle allait aux sucres avec sa mère et le reste de sa famille. Et pourtant l'expression, très canadienne, aller aux sucres ("to go to the sugarbush") s'emploie seulement sept fois dans tout le roman.
C'est la lecture verticale qui permet de regrouper les sept occurrences dans Bonheur d'occasion de aller aux sucres, plus les quatre occurrences de les sucres (ce sens du mot sucre et aussi le pluriel sucres ne se trouvent pas dans le français d'autres parties du monde francophone). La lecture verticale permet aussi d'étudier la fréquence des mots outils dont on est complètement inconscient pendant la lecture linéaire. On peut en fait avoir accès à la fréquence de tous les mots de texte, mots outils et mots lexicaux, par la liste de fréquences. La liste de fréquences du texte "Trois couleurs" révèle plusieurs structures du texte, qui sont des structures que l'on retrouve dans tout texte ou ensemble de textes :
• a) Les mots les plus fréquents sont des mots outils (de, à, l', est, son, un, et, etc.).
• b) Le mot le plus fréquent est de.
• c) La fréquence la plus nombreuse est la fréquence 1, celle donc des mots, ou plus précisément formes (par exemple, l'article le se manifeste dans le texte sous les formes le, la, l' et les), qui ne s'emploient qu'une fois dans le texte ou corpus de textes.
• d) Les mots thématiques (mots lexicaux choisis parmi les mots disponibles pour traiter du thème du texte) ont une fréquence anormalement élevée par rapport à leur fréquence dans un grand corpus de langue (cf. le modèle du British National Corpus).
Regardons ces structures de plus près. On peut figurer la distribution des fréquences sous forme d'une courbe graphique, qui est celle de tout texte ou ensemble de textes :
| Fréquences
| 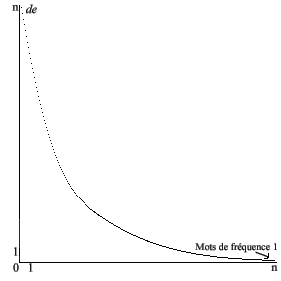
Nombre de mots
|
Courbe normale de la distribution des fréquences d'un texte ou corpus de textes
L'axe vertical donne la fréquences des mots (de 1 à n).
L'axe horizontal donne le nombre de mots (de 1 à n) par fréquence.
|
En ce qui concerne les mots thématiques, on remarque : mari (même fréquence que celle des mots outils ce, d', dans, des, du, les et une) ; bleu, dominique (= Dominique), julie (= Julie), kieslowski (= K...), liberté, trilogie, valentine (= V...) et vie (qui ont la même fréquence que le, qui et sa). Dans un texte plus long (comme, par exemple, le roman Bonheur d'occasion), les mots thématiques commencent plus loin dans la liste de fréquences, mais ont toujours une fréquence plus élevée que dans un corpus de langue.
La liste de fréquences des mots de "Corpus 56" donne d'abord des mots outils, de en tête, puis on commence à voir apparaître des mots thématiques. L'explication de la fréquence anormale de québec (f 206, la ville de Québec et la province du Québec) et de montréal serait en partie la tendance à la spécificité locale de la presse québécoise. Deux autres mots lexicaux frappent par leur haute fréquence : saint (f 128) et jean (f 103). Il y a dans les articles de nombreuses références à des villes et régions, notamment québécoises, comme Saint-Jean-sur-Richelieu, Lac-Saint-Jean, Saint-Hyacinthe, L'Anse-Saint-Jean Souvent ou au fleuve le Saint-Laurent, plus des noms de personne comme Guy Saint-Pierre. Il y est aussi souvent question de Jean Chrétien, en plus des divers Jean-Marie, Jean-Jacques, Jean-Louis, Jean-Claude, Jean-Pierre ou Jean-Paul, sans oublier certaines des villes et régions mentionnées ci-dessus.