|
|
Plusieurs facteurs peuvent expliquer cette hypertrophie lexicale.
— Tout d’abord, les fautes de frappe (très certainement liées à la trop petite fenêtre de la page du moteur, qui empêche de visualiser plus de 10 caractères consécutifs), d’orthographe et les constructions de mots composés (notamment avec le tiret et l’espace souligné, voire sans rien —l’espace entre les mots étant parfois absent).
— l’usage délibéré d’un français libéré des contraintes orthographiques, par exemple phonétique (kdo) ou humoristique (windaube), de façon à cibler plus efficacement les pages recherchées.
— Au-delà des noms « propres », la présence de mots relatifs aux objets techniques de consommation, qui sont déjà des hétérographes, du fait de la présence variable de l’espace inter-« mots »: F801 17, 900XJ, Photoshop5.0. Ce type de mots est virtuellement infini, puisque tout nombre peut avoir le statut de mot (pensons à 2001, 1914, 3615, 1515, etc.).
|
|
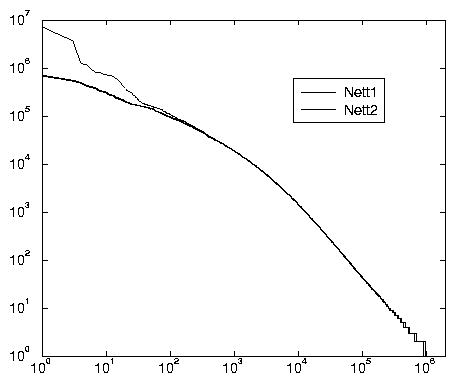
Ce graphique montre qu’une fois passés les mots les plus fréquents, les deux procédures donnent des résultats identiques, qui par ailleurs mettent en évidence une assez bonne conformité du vocabulaire avec la loi de Zipf 18, surtout pour les mots à fréquence intermédiaire (entre 10 et 10 000 occurrences).
L’homogénéité de cette classe de mots, et le souvenir de l’intérêt porté par les lexicométriciens aux mots à fréquences rares nous inciteront à ne pas nous focaliser sur les mots à fréquences majoritaires, même si ces derniers ont un poids considérable dans le corpus, comme le montrent les tableaux 2.3 et 2.4.
|
|
|
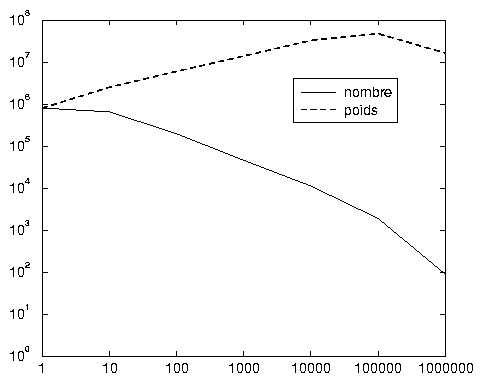
Après avoir évité ce premier piège, qui consiste à se focaliser sur les mots les plus fréquents, nous retiendrons que la moyenne d’usage des mots est élevée, comprise entre 70 et 78 suivant la méthode choisie, alors que le taux d’hapax ne s’écarte pas trop des normes « littéraires »: 48 % dans les deux cas. Et le graphique 2.1 rappelle que seulement 250 000 mots —soit moins de 15 %, avec l’une ou l’autre méthode— apparaissent plus de 10 fois en 88 jours. En revanche, l’agrégation que proposent le tableau 2.6 et le graphique associé 2.2, met bien en évidence le très petit nombre de mots à fréquences élevées, et l’importance en taille comme en poids des mots aux fréquences faibles (par exemple entre 2 et 10 000).
|
|
|
En effet, 86 % des mots apparaissent entre une et dix fois dans cette longue période.
Certes, nombreux sont les mots mal orthographiés (souvent des mots composés sans séparateur, comme « galleriephoto » ou « comparaisonsautos »), Or, si ceux-ci risquent fort de renvoyer un message d’erreur de la part du moteur de recherche, ils apportent néanmoins du sens et témoignent d’une variété des pratiques plus instructive que la simple présence de mots banals.
Par exemple, pour les données des 88 jours du printemps 2001, on a dénombré 4820 mots contenant la graphie « photo » (photoaerienne, photoshop, photo_arbre_hevea, www.hp-photoworld.com, pphoto, etc.); 433 mots contenant la graphie « peugeot », 274 contenant la graphie « apple », et 186 la graphie « microsoft » (Procédure Nett1). On pourrait regrouper ces formes avec la forme attendue, qui reste largement majoritaire: on dénombre 60 493 occurrences pour le mot exact « peugeot », quand la seconde forme est bien plus rare —www.peugeot.fr, avec 290 occurrences 21. Mais nous savons qu’une telle démarche est hâtive. En revanche, les formes rares dévoilent donc un sens précis. Considérons par exemple le mot « chomage »: il apparaît 16 885 fois, et ses formes dérivées (au nombre de 56) apparaissent au total 224 fois. Parmi les formes graphiques les plus rares, on recense emploi-chomage (12 occurrences), couverture-chomage (4 occ.), ainsi que chomage2000, chomage.com, assurance-chomage (4 occ. aussi), et enfin les hapax denonciatiochomage et definitionduchomageenfrance. Paradoxalement, ces dernières formes font sens pour la personne qui analyse les requêtes, alors que d’autres, peut-être pertinentes pour le moteur, seront plus difficiles à interpréter.
Parmi ces mots rares, nous découvrons aussi des mots de notre vocabulaire courant: en trois mois, heterodoxe apparaît 10 fois, comme horlogeries (qui apparaît 2755 fois au singulier), hydroxydes est repéré 6 fois, comme ineligibles (qui apparaît 4 fois au singulier), inquietante ou insatiablement. De même, analytiquement n’apparaît que 4 fois —et psychanalytiquement une seule—, scintillographie 3 fois, soliloquer et soliloque une fois (procédure Nett2). Autrement dit, éliminer les mots à faibles fréquences consiste à réduire notre langue sans discernement.
Ce fait est particulièrement flagrant dans le cas des personnes. Des auteurs comme Pierre Bourdieu ou Julien Gracq 22 ne sont cités que respectivement 1679 fois (rang 9050) et 290 fois (rang 29 759). C’est faible face à Molière 23. Le géographe Marcel Roncayolo a bien moins de succès avec 24 occurrences, et un rang de 148 568, soit autant que Jean-Claude Chamboredon (rang 146 118), à peine plus que Gérard Noiriel (23 occ., rang 152 429) ou Jack Goody (21 occ., rang 161 065), mais déjà loin devant Philippe Descola (12 occ., rang 230 696).
Ces exemples prouvent à quel point il est dangereux de négliger les mots rares: non seulement, on fonde l’analyse sur les mots les plus courants, souvent les plus polysémiques et les moins explicites, mais on risque de perdre des pans entiers de la culture maîtrisée —ou sollicitée— par les internautes.
Cette insistance sur les mots rares répond aux quelques études disponibles sur les requêtes des moteurs. Celles-ci ont une fâcheuse tendance à valoriser les « têtes de listes » que sont les mots à fréquences majoritaires, en les décontextualisant de façon artificielle: beaucoup sont des fragments de syntagmes nominaux; et l’on verra que ces mots courants apparaissent fréquemment comme des requêtes complètes. Dans une telle situation, on ne peut rien déduire de l’intention de l’émetteur.
Nous comprenons donc qu’il est nécessaire, pour mener une étude efficace, d’oublier les mots fréquents, ou, au moins, de ne pas se focaliser sur leur fréquence.
|
|
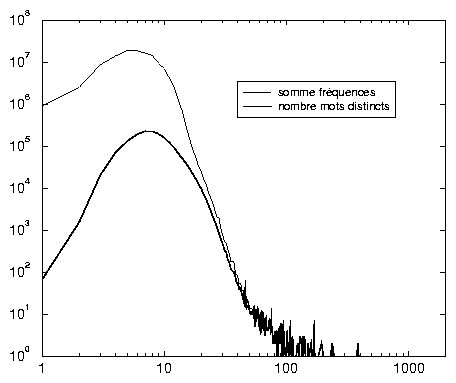
Tout d’abord, le graphique 2.3 décrit la distribution des mots (distincts ou cumulés) en fonction de leur longueur: si l’on rencontre un mot de 1099 caractères et un autre de 1456, les mots les plus fréquemment cités ont entre 3 et 12 caractères, la grande majorité des mots distincts en a entre 5 et 11 24 (procédure Nett2). On remarque aussi que ce groupe de mots entre 5 et 11 caractères est le plus représenté, puisqu’il correspond à 87 539 884 occurrences, soit encore 73 % du total des fréquences. La superposition des deux courbes permet d’avoir une idée de la fréquence d’apparition des mots d’une longueur donnée: autant on conçoit que les courbes soient très proches pour les grandes longueurs (de tels mots apparaissent rarement plus de deux fois), autant les fortes répétitions de mots courts surprennent; 68 mots de longueur 1 générent à eux seuls 900 420 occurrences, et 1524 mots de longueur 2 en génèrent 2 468 056. Certes, on sait qu’un seul mot de longueur 4 en génèrera près de 700 000, mais que pèse-t-il face à ces 1590 mots brefs?
|
|
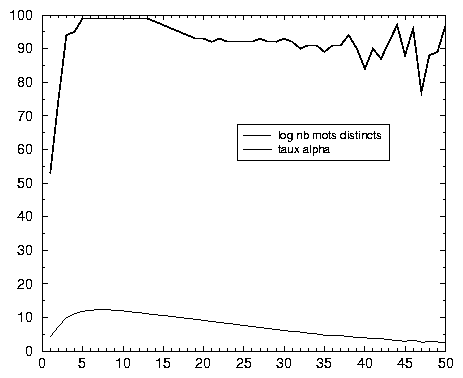
Reste à comprendre la forme de ces mots. Le graphique 2.4 donne le pourcentage de mots exclusivement composés de lettres de l’alphabet en fonction de leur longueur. Est rappelée, en bas du graphique, la fréquence de ces mots. On constate ici que les mots qui ont le plus de chance d’apparaître dans un dictionnaire 25 sont les mots de longueurs 5 à 13, puisque leur taux d’homogénéité interne dépasse 99 %. Et ce graphe permet de mieux comprendre la forme des mots courts: ce sont surtout des abréviations ou des combinaisons de chiffres et de lettres 26.
Le tableau 2.7 met en évidence cette singularité lexicale, tout en rappelant que la grande majorité des mots est, comme on l’a déjà vu, composée exclusivement de caractères alphabétiques.
|
De tels regroupements rappellent ceux relatifs aux connecteurs de la première procédure. Ils mettent en évidence des usages qui nous semblent plus pertinents que ceux que décrivent les conclusions relatives aux mots les plus fréquents. Par exemple, parmi ces « mots-nombres », on dénombre 877 numéros de téléphone 27, pour 1252 occurrences. Cela signifie que certains utilisateurs imaginent que Goosta offre aussi les fonctionnalités d’un annuaire inverse 28 —d’ailleurs très demandé (rang 21, pour 44 681 occurrences).
Nous découvrons aussi à quel point une étude approfondie est coûteuse: elle nécessite du temps (temps de l’homme, temps de la machine), et sollicite diverses disciplines. Pourtant, notre travail ne fait que commencer: le besoin se fait sentir d’étudier les requêtes elles-mêmes, les sessions, et enfin de tenter de cerner leurs auteurs.
Enfin, nous découvrons un étrange dictionnaire: comme les mots de tous les jours, il renvoie à une culture grand public, avec des mots éphémères (starlettes et starletons 29, mots d’actualité, etc.), et les fautes de frappe ou d’orthographe sont communes. Mais il témoigne aussi d’une explosion du vocabulaire, fruit de l’industrialisation (médicaments, noms de marques, pièces techniques, etc.) et il est difficile de savoir si cette « explosion » de ces mots exclus de la littérature a un lien ou pas avec la transformation des techniques d’appropriation et de recomposition de l’écriture.
Cette variété du vocabulaire aura eu le mérite de nous faire prendre conscience que, même si nous écrivons avec peu de mots, un bien plus grand nombre nous encombre l’esprit. Nous y reviendrons.