|
|
Cette étude est a priori source de désarroi: les représentations conventionnelles, les échantillonnages habituels ne fonctionnent pas. Mais elle est aussi très instructive sur le plan méthodologique: les phénomènes majoritaires sont peu pertinents, quand les plus informatifs sont rares. Mais d’autres faits bousculent encore nos préjugés.
|
|
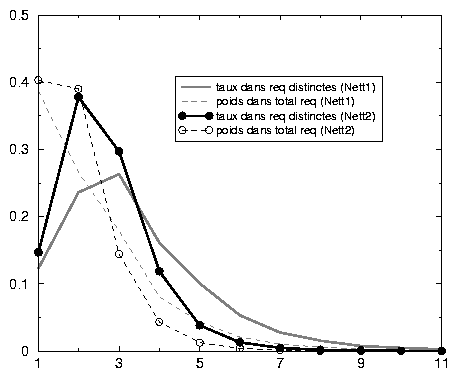
Au-delà de ces nuances, un invariant s’impose: quelle que soit la méthode utilisée, les requêtes composées d’un seul mot constituent 40 % du total en nombre d’occurrences 50. Ici encore, les requêtes qui, dans une vision statistique primaire, sont les plus remarquables, sont aussi les moins instructives: pour faire retour à ce que nous avons déjà démontré, on ne dénombre que 7 requêtes de trois mots ou plus dans les 1000 premières, ce qui est fort peu. Pour les 9000 suivantes, ce type de requête ne s’élève qu’à 338.
Qu’obtenons-nous si nous oublions ces requêtes aussi pesantes que vides? Un simple argument de combinatoire permet de comprendre que, plus une requête est longue, plus sa fréquence est faible. Ainsi, l’intérêt des requêtes minoritaires, et parmi elles les requêtes longues, est triple: déjà, ce sont elles qui enrichissent le vocabulaire. Ensuite, la probabilité pour que l’internaute tire satisfaction de sa question au moteur est plus grande que pour une requête courte 51. Enfin, son intention est compréhensible pour l’analyste.
|
Il en est de même pour les requêtes de plus de 10 mots, dont voici le détail des cinq premières: « tableau recapitulatif tous microprocesseurs amd intel actuel venir ainsi que leurs caracteristiques » (48 occ.), « marie elise eugenie crepin nee 28 mars 1871 forest montiers somme » (40), « est ce que echanges entre partenaires sociaux modifient concretement aide qu animateur apporte jeunes difficulte elaborer realiser leur projet vie » (34), « cours universitairse informatique droit aes sciences politiques ressources » (30), et « redaction une note synthese mise reseau ordinateurs routeurs administrateur reseau entreprise » (29).
D’une part, le sérieux apparaît: point de requêtes frivoles ou naïves ici. D’autre part, nous comprenons mieux comment se construisent les sessions: la probabilité est grande que ces requêtes de plus de 10 mots soient chacune des éléments d’une même session. Outre la spécificité du vocabulaire (« Mme Crépin », etc.), la présence de fautes de frappe corrobore cette intuition (universitairse).
Reste, avant de donner quelques exemples, puis de décrire les sessions, à montrer comment cette richesse lexicale se construit avec le temps.
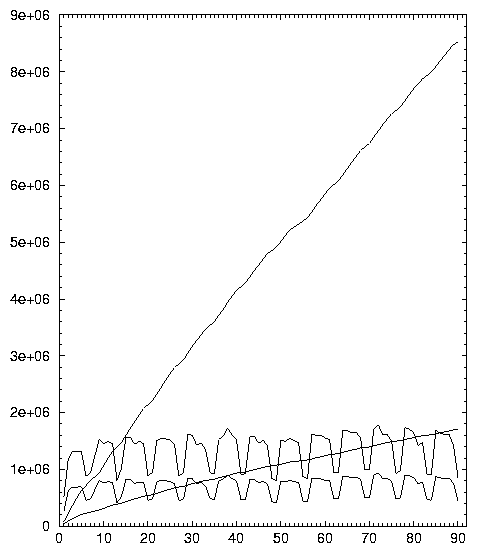
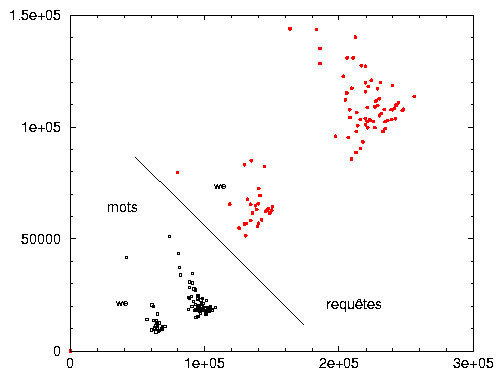
Ce résultat, qui peut sembler déroutant, est synthétisé dans le graphique 2.13 et appelle tout de suite une remarque méthodologique. En effet, nous pouvions penser que le nombre de requêtes distinctes fût estimé aisément à partir d’un sondage réduit du corpus, en limitant par exemple l’échantillonnage à une semaine. Il n’en est rien: étonnamment, ce nombre semble proportionnel à la durée. Même à la fin de l’échantillon temporel, entre les 55e et 88e jours, le nombre de nouvelles requêtes croît encore d’environ 97 000 par jour. Et ces nouvelles requêtes ne sont comptées qu’une fois 53. Ainsi, même après une simplification drastique (ici la procédure Nett2), le taux de nouvelles requêtes par jour compose environ un septième du total des requêtes (alors que ces dernières sont comptées autant de fois qu’elles apparaissent). La lecture du graphique 2.14 montre qu’en fait, en période de semaine, les nouvelles requêtes (toujours comptabilisées une seule fois) constituent au moins 40 % des requêtes distinctes de chaque jour. On pourrait alors interpréter ce phénomène comme une conséquence d’une activité combinatoire des internautes à partir d’un lexique donné, fixe au bout d’un certain temps. La croissance du nombre de mots avec la taille de l’échantillon montre que cette hypothèse est fausse. Celle-ci est aussi linéaire avec le temps (en moyenne 20 000 nouveaux mots par jour, cf. graphique 2.13), et ces nouveaux mots constituent au minimum 15 % des mots distincts de chaque jour (cf. graphique 2.14).
|
|
|
|