|
|
Ces précautions prises, nous pouvons nous intéresser non pas au sens des requêtes, mais à certains des thèmes qu’elles pourraient évoquer. Pour cela, nous proposons des outils lexicométriques simples, mais robustes.
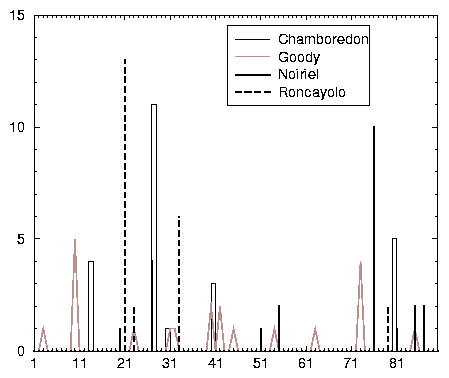
Commençons par un constat, qui rappelle l’importance du temps long. Les requêtes contenant exactement le mot gracq apparaissent presque tous les jours, mais rarement plus de dix fois par jour. En revanche, les références au mot roncayolo sont rares: 13 occurrences le 21e jour, 6 le 33e, une le 51e et 2 le 79e. Il en est de même pour goody, mieux distribué dans le temps, mais n’apparaissant jamais plus de 5 fois dans une journée. Le graphique 2.15 rappelle la distribution de ces noms d’érudits rarement cités.
|
|
Mais cette démarche, qui consiste à chercher un mot dans une liste de requêtes, peut-être améliorée. Puisque nous avons remarqué de grandes oppositions entre des requêtes brèves et vagues, mais nombreuses, et d’autres, précises et rares, nous pouvons tenter de corréler les thèmes des requêtes à leurs caractéristiques lexicales.
L’idée est simple: nous définissons une liste de mots susceptibles d’avoir le même profil (comme anpe et emploi) et repérons les mots qui leur sont associés dans l’ensemble des requêtes; puis nous calculons le « taux de cooccurrence » de chaque mot trouvé avec les mots de la liste initiale. Par exemple, offre apparaît 26 357 avec emploi, et 43 728 fois en tout. Il a donc un taux de cooccurrence de 60 % avec emploi. Autrement dit, il n’y a que quatre chances sur dix pour que offre n’apparaisse pas avec emploi à ses côtés.
Quelques sondages montrent qu’un taux de cooccurrence de 30 % est déjà fort élevé. Avec cette méthode lexicale, on retrouve des synonymes, des segments répétés (même si dans le cadre d’une requête, ceux-ci peuvent être inversés), et l’on se constitue au fur et à mesure une liste de base de plus en plus consistante, qui finit par être composée des parties suivantes:
À partir de là, un programme bref (57 lignes) mais nécessitant quelques heures-machine, sélectionne les requêtes (procédure Nett2) qui satisfont à nos contraintes. Celles-ci sont présentées avec leur nombre d’occurrences, et, à titre de vérification, avec le mot à l’origine de leur sélection.
On dispose ainsi d’un sous-corpus thématique que l’on peut étudier plus précisément. Dans une version améliorée, le programme calcule, pour chaque mot trouvé, son taux de cooccurrence avec la totalité du lexique de base.
|
Appliquée au sexe, l’étude fait apparaître 2 145 012 requêtes, dont 152 071 distinctes. Les requêtes à connotation pornographique ne dépassent donc pas 3,5 % du total des requêtes. Au vu de la façon dont l’internet permet une exploration intime secrète, sans médiation (du vendeur de journaux pornographiques par exemple) ni contrainte juridique (on peut chercher à l’étranger ce qui est interdit en France), ce taux apparaît assez faible.
La seconde étude, destinée à mettre en évidence les préoccupations professionnelles des internautes, montre que le total des requêtes sur ce thème est de 1 169 990, soit 2 %. C’est plus que ce qu’on attendait, surtout si l’on garde en mémoire les discours relatifs à la morale, ou à l’opposé, à la publicité, qui valorise un internaute consumériste et sans soucis. D’autant que les requêtes distinctes sont ici plus nombreuses que dans le thème précédent: 161 628.
La troisième est réservée à une informatique professionnelle, spécifique aux programmeurs et aux adeptes de l’écriture informatique: c’est pourquoi des mots de « consommation courante », comme napster, mp3 ou windows n’ont pas été retenus, et que les requêtes relatives à des recherches d’URL ont été délibérément rejetées. La méthode est donc stricte, et les résultats surprenants: on dénombre ainsi 61 038 requêtes distinctes, pour un total d’occurrences de 293 848.
L’étude des sessions nous fera découvrir d’autres résultats, mais d’ores et déjà, on est étonné par le nombre de requêtes simples dans le registre pornographique: les requêtes d’un mot sont 889 960, soit 41 % du total, quand ce taux baisse à 29 % pour les requêtes relatives aux préoccupations professionnelles (337 025 requêtes) et à 27 % pour la thématique informatique (79 959 requêtes). On découvre aussi un autre résultat très significatif: pour le premier thème, le poids des requêtes de deux mots est inférieur à celui des requêtes d’un seul (795 113), alors que c’est le contraire (465 276 et 118 137), pour celles des deux autres thèmes.
Dernier point, les requêtes à caractère pornographique composent un vocabulaire de 32 900 mots distincts quand celles du second thème sont plus riches: 40 210 mots distincts (et celles du troisième contiennent 18 708 mots). Déjà, ces quelques indicateurs montrent comment on peut à la fois cerner de façon exhaustive et précise (notamment grâce aux listes de mots rejetés) un ensemble de requêtes liées à un thème, et mesurer sa popularité autrement qu’en faisant de simples additions de fréquences de mots souvent polysémiques s’ils sont pris seuls.
Le quatrième thème est celui de l’informatique au sens large, qui intègre les pratiques de consommation —incluant la recherche de biens culturels comme les logiciels et les extraits musicaux—, et des pratiques plus intellectuelles, qui vont du désir de bien faire fonctionner son ordinateur (quitte à apprendre le mode d’emploi d’un logiciel ou d’un modem) à la recherche d’un anti-virus ou d’un firewall pour protéger ses données. Il englobe l’informatique des spécialistes. Le tableau 2.12 décrit la façon dont il est construit (et montre la difficulté à repérer sans erreur l’intérêt pour les produits Windows).
|
Le tableau 2.13 récapitule l’ensemble de ces résultats, tout en introduisant d’autres indicateurs.
|
|
Ces quelques exemples, représentant déjà 9 % du total des requêtes, auront rappelé le danger des interprétations rapides, et mis en évidence, grâce à quelques indicateurs simples, la variété des besoins des internautes, et la relation —heureusement prévisible, mais rarement citée— entre leurs besoins (culturels, financiers, etc.) et leurs motivations.
Nous sommes en effet impressionné par le caractère pluri-dimensionnel des usages: le type des mots et requêtes rencontrés, leurs fréquences, leurs emplois invitent avant tout à la réserve, en même temps qu’ils soulèvent des questions informatiques et méthodologiques aussi essentielles que passionnantes.
Ces premières descriptions devraient maintenant nous permettre de prolonger l’étude jusqu’aux auteurs de notre étrange liste.