|
|
Une session est une série de questions d’un « même » utilisateur au moteur, qui doivent se succéder dans un intervalle de temps « raisonnable », limité ici à 20 minutes. Nous ne pouvons savoir si, durant une session, l’utilisateur reste systématiquement sur le moteur de recherche ou pas: il peut par exemple aller et venir entre le site du moteur et les pages des réponses qui lui sont proposées; ce qui importe, c’est que s’il émet ou répète 1 plusieurs requêtes, chacune apparaisse moins de 20 minutes après la précédente.
Le moyen idéal pour repérer une session est le cookie, identifiant unique. Mais certaines personnes refusent les cookies. Dans ce cas, un nouveau cookie leur est attribué, même en cas de répétition de la requête: ainsi une personne qui refuse les cookies donne l’impression d’effectuer plusieurs sessions, et il faudra corriger ce type de biais. Par la suite, le cookie servira aussi à repérer plusieurs sessions d’un même utilisateur, ce qui nous aidera à décrire des profils d’usages.
La réalisation des programmes permettant de reconstruire les sessions est un vrai casse-tête chinois; elle nécessite des centaines d’heures de travail —et parfois autant d’attente pour obtenir les premiers résultats. C’est pourquoi les résultats de cette partie se limitent à un échantillon réduit du corpus tiré de la procédure Nett2: la semaine du 1er au 7 mars 2001 (incluant un week-end).
Comme chaque cookie intègre sa date de création, les second et troisième champs de ce nouveau fichier sont redondants. Nous commençons alors par tenter de reconstituer les sessions des personnes refusant les cookies: pour un numéro IP donné, nous définissons comme « proches » deux requêtes consécutives (dans un délai réduit, avec les contraintes évoquées précédemment) si on retrouve au moins la moitié des mots de la plus courte dans la plus longue 4. Les deux requêtes sont alors intégrées dans une même session. Il suffit ensuite d’entamer une démarche itérative.
Le tableau 3.1 explique une telle situation: au début, la requête est répétée, ensuite, elle se complexifie, mais on retrouve toujours plus de la moitié des mots de la requête la plus courte dans la plus longue.
|
Avant d’être finalisé sous la forme que nous expliquons, l’algorithme a été testé sur plusieurs cas de figure, et affiné. Sa fiabilité est accrue du fait que nos requêtes sont fortement nettoyées. Il permet de reconstruire 26 493 « sessions-individus » pour 114 343 requêtes, soit une moyenne de 4,32 requêtes pour une telle unité quand cette moyenne est de 4,42 pour les sessions avec acceptation de cookies: les écarts sont faibles.
Après cette reconstitution des sessions avec refus de cookie et de longueur supérieure à deux, nous nous intéressons maintenant aux sessions de longueur 1. Pour éviter celles avec refus de cookie qui n’ont pu être traitées par l’algorithme, nous repérons, parmi les requêtes restantes, celles dont le cookie associé date d’avant mars 2001. On en dénombre 245 054.
Au total, on obtient 5 034 395 requêtes pour 1 328 309 sessions, soit une moyenne de 3,79 requêtes par session. Le reliquat, oublié, correspond à 5,6 % du total des requêtes: un millier dû aux sessions reconstituées mais rejetées à cause d’incohérence des dates des cookies 6, diverses sessions que nous n’avons pas réussi à reconstituer, des sessions de longueur 1 de nouveaux utilisateurs 7, etc.
Nous pouvons alors estimer le taux maximal de personnes refusant les cookies: les requêtes rejetées sont au nombre de 296 614. Elles s’intègrent dans des sessions avec refus de cookie, mais non reconstituables, et dans des sessions de longueur 1 réalisées par des nouveaux arrivants. En négligeant ces derniers et en appliquant les résultats obtenus avec les requêtes conservées pour l’étude, nous estimons à environ 78 000 les sessions avec refus de cookies qui ne sont pas prises en compte. En les ajoutant aux 26 493 reconstituées, cela nous donne environ 100 000 sessions avec refus de cookie. Sachant qu’on obtient une « moyenne » de deux sessions par individu (on sait que cette notion n’a de sens que pour des estimations grossières), on peut évaluer à 7 % le taux de personnes refusant les cookies 8.
Notre choix mérite donc une explication, car certains analystes partent du principe que la syntaxe de l’utilisateur témoigne de sa capacité à maîtriser la logique du moteur de recherche 9. Ce dont nous doutons, pour plusieurs raisons: comme le proposait Google à ses débuts (printemps 2000), il est inutile de raffiner une requête avec des « + », des « - », des « et », des « ou », des guillemets si le moteur est efficace. A charge pour l’utilisateur de compléter sa requête avec d’autres mots-clés si le nombre de réponses est trop élevé. Ce que font les chercheurs expérimentés 10, que l’on devrait classer parmi les personnes à faible compétence documentaire si l’on acceptait le préjugé que nous critiquons; d’autre part, la syntaxe du moteur étudié est mal connue des utilisateurs. À l’occasion de nos nettoyages des requêtes, nous avions remarqué de nombreuses expressions commençant par des guillemets, mais sans guillemets finaux, dotées de symboles « ++ » ou « && »; enfin, les réponses du moteur sont ambiguës: par exemple, la requête « "atelier internet" » renvoie de façon très approximative aux pages contenant cette expression, puisque dans les dix premières réponses, nous avons trouvé une page ne contenant nulle part l’expression recherchée 11, mais l’expression « atelier sur internet ». De même, la requête « pamela -anderson » permet bien de retrouver des pages sans le mot anderson, chose impossible avec la requête « pamela - anderson ».
Aussi, le raffinement de requêtes avec des opérateurs booléens et des expressions complexes ne peut-il être la preuve que d’une maîtrise relative, mais assurément non complète, de l’informatique documentaire. Et il suffit d’une erreur (de l’utilisateur, ou de l’algorithme du moteur 12) pour que ces requêtes dites complexes ne soient pas efficaces. Cette insistance des analystes des logs sur les opérateurs booléens témoigne avant tout du respect pour une tradition de recherche qui n’a plus d’intérêt à nos yeux: les travaux de Silverstein datent de 1998, à l’époque où AltaVista —employeur du chercheur— s’imposait comme le meilleur moteur, grâce à cette possibilité d’insérer des opérateurs booléens.
Tout d’abord, ont été repérés les mots et requêtes fréquents, communs ou rares: mots apparaissant plus de 1500 fois (les 10 000 premiers 13), entre 1500 et 100 fois (seuil correspondant à une apparition par jour en moyenne et au rang 60 000 14), et les... 97 % d’autres; requêtes apparues plus de 500 fois (environ les 10 000 premières, couvrant assez bien les 10 000 premiers mots), entre 500 et 20 fois (ce qui mène au rang 300 000 15), et autres.
Nous calculons alors, pour chaque session, les nombres de mots distincts fréquents, communs ou rares de la session 16, et faisons de même pour les requêtes. S’en déduisent les indicateurs typmot et typreq, qui ont les valeurs -1 (rare), 0 (commun) ou 1 (fréquent), définies par la présence d’un mot ou d’une requête de plus bas rang 17, et la taille du lexique de la session (nombre de mots distincts).
Nous dénombrons aussi le total des occurrences de mots (avec répétition), le nombre maximal de mots des requêtes, et bien sûr la longueur de la session (nombre de requêtes). Ensuite, le nombre de répétitions des requêtes 18, qui permet de se faire une idée du nombre de requêtes distinctes d’une même session. Enfin, la présence ou absence de requêtes dites « simplistes » dans la session (requêtes exclusivement composées d’un numéro de téléphone, ou d’une URL) et la durée de cette dernière.
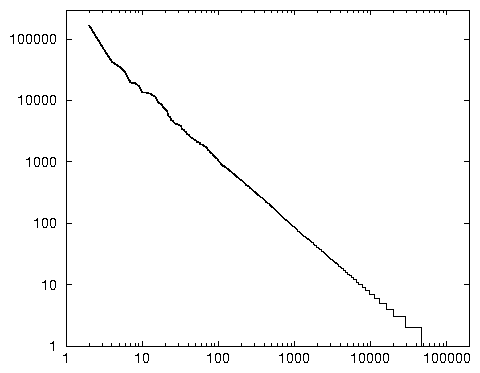
Bien sûr, certains indicateurs s’avèrent corrélés à d’autres (comme le total des occurrences de mots, s’accroissant automatiquement quand une requête est répétée). Mais, au vu des travaux du chapitre précédent, on ne s’étonnera pas de rencontrer une grande variété de « types » de sessions, même si l’on simplifie de façon draconienne 19 les indicateurs ainsi construits, et bien qu’aucune spécificité thématique n’ait été introduite: à partir des sessions étudiées, nous obtenons 150 050 profils différents; si le premier réunit 168 480 sessions, 70 % des profils n’apparaissent qu’une fois, ce qui signifie que 8 % des sessions sont absolument hors-normes. Le graphique 3.1 met en évidence cette structure, qui manifeste l’importance des profils de sessions atypiques et qui montre que les types de sessions se distribuent eux aussi selon une loi de puissance.
|
|
L’objet étudié ici, la session, est bien plus homogène que le mot ou la requête. Ceci-dit, nous n’étudions encore que des « micro-phénomènes », qui ne correspondent pas vraiment à des réalités sociologiques: ce n’est pas en comptant le nombre de fois qu’une personne entre dans une église qu’on peut en déduire qu’elle est pratiquante; un questionnaire, où elle répond par oui ou par non à la question posée, est autrement plus révélateur. Même quand nous regrouperons les sessions pour tenter de décrire des pratiques humaines, il conviendra de se remémorer cette situation: comme lors de l’étude des mots et requêtes, nous devrons rester particulièrement vigilant quant à l’interprétation des résultats statistiques relatifs aux sessions. Et ces précautions nous permettront de proposer quelques descriptions qui, à notre connaissance, n’ont pas été réalisées à ce jour.
38 % des sessions sont de longueur 1 et 69 % d’entre elles sont de longueur au plus 3. À l’opposé, 23 % des sessions ont une longueur supérieure ou égale à 5. Ainsi, les sessions courtes sont majoritaires. De façon analogue, 19 % des sessions ont un total d’occurrences de mots réduit à... 1, quand ce dernier dépasse 10 pour 20 % des sessions.
Pour la grande majorité des sessions, les requêtes aussi sont courtes: 35 % des sessions sont composées de requêtes d’un mot. 75 % des sessions sont composées de requêtes d’un ou deux mots. À l’opposé, seulement 8 % des sessions contiennent une requête d’au moins 4 mots.
Le lexique est le nombre de mots distincts d’une session. 29 % des sessions ont un lexique de taille 1; ce qui signifie que près d’une session sur trois est composée d’une seule requête d’un seul mot, éventuellement répétée. 59 % des sessions ont un lexique de taille inférieure ou égale à 2 et 75 % en ont un de taille inférieure ou égale à 3. Elles ne sont que 15 % à disposer d’un lexique de taille supérieure ou égale à 5.
34 % des sessions ne contiennent que des requêtes fréquentes (et 53 % au moins une requête fréquente); 58 % des sessions ne contiennent aucune requête rare quand 16 % contiennent au moins 2 requêtes rares. De même, 55 % des sessions ne contiennent que des mots fréquents et 79 % ne contiennent aucun un mot rare. 5 % contiennent au moins deux mots rares.
Le nombre de répétitions témoigne d’une certaine insistance de l’utilisateur. Par exemple, une session avec quatre répétitions peut être composée d’une même requête lancée 4 fois (ce qui signifie que l’internaute a jeté un œil sur les 50 premières réponses), ou de quatre requêtes lancées chacune deux fois 20. 54 % des sessions ne contiennent aucune répétition, quand 11 % en contiennent plus de 5 (et 4 % plus de 10). Cela signifie que dans la moitié des sessions, les utilisateurs ne cherchent pas à consulter la seconde page de résultats du moteur. Sont-ils satisfaits des premières réponses, reformulent-ils leur question, ou partent-ils visiter un autre moteur? Nous ne pourrons pas répondre à ces questions, sauf partiellement à la seconde.
Par ailleurs, on dénombre 8758 sessions « simplistes », c’est-à-dire contenant au moins une requête composée exclusivement d’un URL ou d’un numéro de téléphone, témoignant certainement d’un grand malaise de l’utilisateur devant le moteur, qui va de la confusion entre moteur de recherche et annuaire téléphonique inverse à l’incapacité à distinguer fenêtre d’adresse du navigateur et fenêtre d’interrogation du moteur 21.
Il y a deux façons d’analyser ces premiers résultats. Ou l’on considère que « les » internautes posent avant tout des requêtes banales et se satisfont tout de suite des réponses du moteur: les sessions sont très brèves, en temps comme en longueur; pour la moitié d’entre elles, la seconde page de résultats n’est jamais consultée; seulement un quart des sessions ont un lexique de taille supérieure à 4. Cette première hypothèse tend à suggérer que, ou le moteur est très performant, ou les internautes se satisfont de peu. Elle ne nous convient pas: si nous nous souvenons que l’internet renvoie à de nouvelles pratiques d’écriture, de recherche (et de lecture sélective), la première idée qui nous vient à l’esprit est que la grande majorité des internautes est déçue ou désemparée. A l’opposé, se dégage un noyau de 10 à 20 % des « utilisateurs-sessions » qui, malgré ces difficultés, ont tendance à se montrer insistants: ils cherchent à parcourir un grand nombre de pages de réponses, n’hésitent pas à rédiger des requêtes non communes, voire complexes, ni à les remanier. Ainsi se dessinent des tendances, des types d’usages.
Mais il ne faut pas pour autant confondre sessions majoritaires et pratiques des internautes. D’une part, nous n’étudions pas encore des « individus »; d’autre part, prétendre que 80 % des sessions ont un profil donné sans rappeler la présence des 20 % restantes reviendrait à retomber dans les errances déjà dénoncées auparavant: les salaires mensuels des Français ne sont pas tous inférieurs à 10 000 F, tout comme leur culture ne se limite pas au contenu du Quizz.
De même, plus maxmots augmente, plus la session risque de contenir des répétitions: par exemple, deux sessions sur trois, parmi celles dont maxmots est supérieur ou égal à 5, contiennent au moins une répétition. Mais 64 % des sessions dont la ou les requêtes ne contiennent qu’un mot sont sans répétition (et 53 % des sessions dont maxmots vaut 2). On peut s’étonner de cette pratique, habituellement réservée aux personnes qui ont l’habitude d’adresser des requêtes très ciblées, quitte à les reformuler si la première page de réponses ne les satisfait pas.
En fait, 55 % des sessions composées de requêtes d’un seul mot sont de longueur 1. Il n’y a donc même pas de réénonciation, ni de poursuite de la lecture des résultats. Ce taux d’abandon (ou de « dérive ») instantané baisse à 35 % pour les sessions où maxmots vaut 2, et à 22 % pour celles il vaut 3: dans l’ensemble, ce taux semble particulièrement élevé.
20 % des sessions composées de requêtes d’un seul mot ont un total d’occurrences de mots égal à 2. Traduit, et combiné avec les résultats précédents, cela signifie que quand un internaute saisit une requête d’un mot, il y a trois chances sur quatre (20 % + 55 %) pour qu’il ait une des trois réactions suivantes:
— il ne dépose aucune autre requête et ne cherche pas à consulter la seconde page de résultats 22;
— il regarde la seconde page et sa session sur Goosta est alors terminée;
— il émet une autre requête d’un mot et là aussi, cela signifie la fin de la session.
Même si on peut admettre que l’internaute utilise le moteur à des fins ludiques (ou didactiques), on est malgré tout amené à penser que dans de nombreux cas, l’usage du moteur conduit plutôt à une forme de « désespoir »: n’oublions pas que 35 % des sessions ne contiennent pas de requêtes de plus d’un mot, ce qui déjà, témoigne d’une faible connaissance du fonctionnement d’un moteur de recherche. Bien sûr, ces sessions sont banales: 60 % d’entre elles ne sont composées que d’un mot fréquent. Le fait que dans 75 % des cas, on retrouve la pratique évoquée ci-dessus donne à penser que si l’internaute n’utilise pas le moteur à des fins de démarrage d’une navigation, il arrête bien vite sa session. D’autant qu’il ne reformule pas sa requête: 81 % des sessions d’un mot (maxmots=1) ne sont pas modifiées. Ces effets d’uniformité se traduisent aussi avec la faible présence des mots rares (de rang supérieur à 60 000): 79 % des sessions n’en contiennent aucun; pour les sessions à requête(s) d’un mot, comme pour celles contenant une requête de deux mots, ce taux est de 81 %. Il baisse légèrement (75 % ... 3 mots) mais reste tout de même à 58 % pour les sessions dont une requête comprend au moins 5 mots. On découvre donc que même ces sessions, dont on pouvait penser qu’elles fussent complexes, contiennent peu de mots rares.
On peut vérifier que la durée d’une session est plus corrélée à un type de matériel qu’à des pratiques intellectuelles. Par exemple, si 81 % des sessions de moins de 5 minutes ne contiennent que des requêtes d’au plus deux mots, ce dernier profil constitue encore 56 % des sessions de 20 à 30 minutes, et 47 % des sessions de plus d’une demi-heure. Les sessions de longue durée ne favorisent donc pas l’expression de requêtes d’au moins trois mots. On ne s’étonnera pas du fait que plus une session est longue en nombre de requêtes, plus elle a tendance à durer, même s’il faut attendre des sessions de plus de 10 requêtes pour qu’elles soient nombreuses à dépasser les 30 minutes (les sessions de longueur 5 à 9 constituent 27 % de ces sessions à longue durée, celles de longueur supérieure à 10, 69 %). De même, plus une session dure, plus la chance qu’apparaisse un mot ou une requête rare augmente. Mais, d’un autre point de vue, les sessions comprenant un total d’occurrences de mots supérieur à 10 se distribuent assez bien dans les classes de temps définies: chaque telle classe 23 comprend au moins 17 % de ces sessions. Certes, il y a là un effet d’écrasement de la distribution, mais on apprécie de ne pas voir de lien direct autre que prévisible entre la durée et le profil de la session.
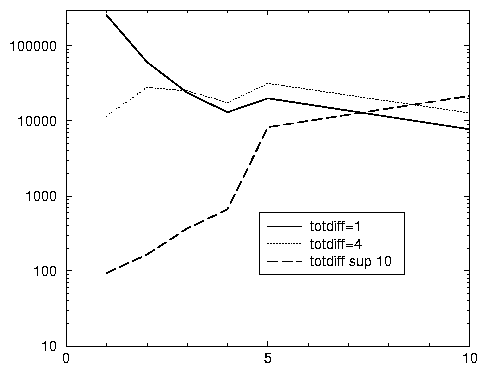
Le croisement de la longueur de la session avec la taille du lexique donne en revanche des informations contrastées: comme prévu, les sessions de longueur 1 dont le lexique n’est composé que d’un mot sont très nombreuses (255 722) et celles de même longueur, mais avec un lexique de plus de 10 mots très rares: 94 exactement. Mais le graphique 3.2 montre aussi un autre phénomène: quelle que soit la taille du lexique, on rencontre un nombre non négligeable de sessions longues, de plus de 10 requêtes (entre 7722 et 41 157 —ceci pour les sessions à lexiques de 5 à 9 mots, non représentées ici 24). Autrement dit, il semble que se dégage une population de curieux, même chez les personnes supposées émettre des requêtes banales. En fait, ce résultat donne à penser qu’on a là au moins deux catégories d’utilisateurs: des personnes qui utilisent le moteur à des fins professionnelles, ou avec une demande précise, et d’autres, plus passives, qui consultent néanmoins de nombreuses pages de réponses. En effet, 30 % des sessions de longueur supérieure à 10 correspondent à des requêtes ne contenant que des mots fréquents. Certes, il faudrait affiner ces analyses, en regardant si ces requêtes sont identiques ou pas. Mais ces 33 274 sessions empêchent de confondre tous les auteurs de requêtes composées de mots fréquents: une minorité parmi les utilisateurs d’un lexique banal a un mode de consultation qui rompt avec la norme (de façon analogue, 38 % des sessions avec plus de 10 répétitions —donc elles aussi de longueur supérieure à 10— ne contiennent que des mots fréquents).
|
|
En revanche, le désir de cibler les requêtes est assez peu présent: si on se rappelle que 21 % des sessions contiennent au moins un mot rare, elles ne sont que 5 % à en contenir au moins deux. Cette proportion s’accroît logiquement avec la longueur des sessions, mais très modestement: 11 % des sessions de longueur 5 à 9 contiennent au moins deux mots rares, et 19 % des sessions de plus de 10 requêtes. La taille du lexique semble être la condition d’apparition de ces mots rares: pour les lexiques de taille 2, le taux de sessions avec au moins deux mots rares est de 2 %. Il double à peu près pour chaque unité supplémentaire, et vaut 42 % pour les 31 004 sessions à lexique de taille supérieure à dix 25.
Si l’on décompose l’ensemble des sessions par types de mots et de requêtes, on obtient le tableau 3.2: 34 % des sessions sont composées de requêtes de type 1, ce qui semble conforme avec le poids des 10 000 premières requêtes (tableau 2.9 page 458).
|
|
Nous comprenons alors que l’intérêt des publicitaires pour les requêtes majoritaires n’est pas seulement sans fondement scientifique: il est aussi suicidaire, puisque celles-ci doivent en grande partie leur importance au comportement des internautes qui fuient au plus vite le moteur. Ces personnes semblent capables de nous proposer un sondage électoral en ne consultant que les personnes dont on sait qu’elles ne voteront pas...
— elle n’est composée que de requêtes fréquentes 26 (typreq = 1);
— elle contient des requêtes fréquentes ou communes d’au plus deux mots, ces derniers étant alors fréquents ou communs;
— son lexique total ne dépasse pas 2 mots, fréquents ou communs.
Les autres sessions sont appelées SNE.
Puisque l’on travaille sur des sessions, et donc sur des ensembles de requêtes, il est clair que la définition d’une SE mérite bien son nom: le seuil de complexité permettant de définir une SNE est on ne peut plus bas. Par exemple, une session composée de la requête « musique reunionnaise », répétée 11 fois, suivie de la requête « zouk » (4 fois) est une SNE. De même pour la session composée des requêtes suivantes: « ucpa », « pep », suivie de « colonies vacances » (2 fois). Ou encore « crous ly » suivie de « crous lyon ».
On dénombre 799 303 SE, soit 60 % des sessions, dont la moitié (51 %) sont de longueur 1, et 20 % de longueur 2. À l’opposé, 37 % des SNE sont de longueur 1 ou 2. Ainsi, la catégorie SE englobe-t-elle 79 % des sessions de longueur 1.
Par construction, les SE ont un lexique réduit: pour 88 % d’entre elles, la taille de ce dernier est inférieure à 2 (43 % de taille 1, 45 % de taille 2). C’est l’inverse pour les SNE: cette taille est supérieure ou égale à 3 pour 82 % d’entre elles (et dépasse 5 dans 34 % des cas).
Nous ne reprendrons pas le détail de la plupart des autres indicateurs: le lecteur sera convaincu, au vu des travaux précédents, que l’on construit là deux classes d’usages distinctes. Nous avons jugé intéressant d’en construire un nouveau, afin d’étudier le lien entre la longueur d’une session et le caractère systématique de ses répétitions: il suffit de repérer les sessions de longueur k composées de k - 1 répétitions.
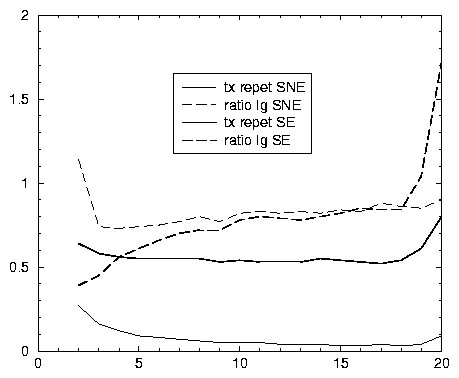
Tout d’abord, pour les SE, la probabilité d’abandon à chaque étape est très forte: 61 % au début 27, pour ne passer en dessous de 1/2 que si la longueur dépasse 4. Mais il ne reste alors plus que 19 % des SE. Le phénomène est inverse pour les SNE: il y a plus de sessions de longueur 2 que de longueur 1, et les sessions de longueur 4 ou plus constituent encore 48 % des SNE; de façon générale, pour les SNE, ce taux d’abandon à chaque étape est constant et faible: aux alentours de 20 %. 27 % des SE sont en fait composées d’une seule requête adressée plusieurs fois (donc avec autant de consultations de pages de résultats), contre 11 % des SNE (et 21 % en moyenne). Cette différence, a priori faible, traduit de fortes oppositions entre SE et SNE, comme le montrent le tableau 3.4 et le graphique 3.3 (pages 559 et 562).
|
Nous voyons se profiler, non pas deux catégories de populations (un individu réalisant une SE peut très bien réaliser une SNE plus tard, et inversement), mais d’attitudes. Avec la première (SE), la requête, souvent banale, n’est pas modifiée, mais il y a recherche d’un lien intéressant, quitte à consulter plusieurs pages successives de réponses, jusqu’à abandon du moteur 28. Il est clair que cette démarche n’est pas optimale, mais on ne peut que s’étonner devant une telle insistance: elle témoigne ou d’une certaine passivité, ou d’une curiosité risquant fort de mener à l’insatisfaction (les requêtes sont banales). La seconde privilégie la rédaction de requêtes plus complexes et leur reformulation en cas de non satisfaction.
|
|
Le graphique 3.3 met en évidence une autre situation: quand la longueur d’une session dépasse 10, la tentation de prolonger cette session est forte, de 80 %, et ce, indépendamment de son type. Il semble que, passé un effet de « surcharge cognitive », les attitudes de type SE se confondent avec les autres. Ce fait est à relier avec celui découvert avec le graphique 3.2 de la page 548: il existe des modes de curiosité indépendants du type a priori de la session (banalité, taille du lexique). On remarque, aussi, pour les deux catégories, des comportements étranges lors des longues SE: la probabilité de consulter une page supplémentaire augmente quand la longueur dépasse 18, et il y a plus de sessions de longueur 20 que de longueur 19.
Ce travail sur les sessions était aride, mais indispensable. Pour décrire les 95 % des sessions réalisées durant une semaine, nous avons construit des indicateurs dérivés de notre étude précédente relative aux mots et requêtes. Diverses statistiques, complétées par la mise en évidence de certains comportements, nous ont prouvé que les sessions sont majoritairement simples et brèves.
Cette étude s’éloigne clairement des thèmes de sociologie-marketing communément rencontrés. Certes, nous avons montré à plusieurs reprises leur inconsistance, ce qui nous permet maintenant de mieux comprendre le grand nombre de faillites des start-up de l’internet. À condition de mener un travail rigoureux, de tester pas à pas des hypothèses avec des mesures exhaustives, de construire un raisonnement scientifique, il appert que le thème qui s’impose est celui du rapport de nos co-auteurs de listes à l’écriture contemporaine. Ils sont engagés dans un double processus d’écriture et de lecture sélective, qui n’a rien d’évident ni d’acquis. En l’occurrence, 60 % des sessions témoignent d’une très faible maîtrise de l’internet.
Mais ces résultats ne nous permettent pas encore de déduire des profils d’utilisateurs: d’une part, nous ne savons pas encore si certains auteurs d’un type donné de session (par exemple élementaire, de longueur 1, etc.) réalisent à d’autres moments des sessions d’un autre type (non élémentaires, etc.) ou pas. D’autre part, la distribution du profil des sessions —et les résultats précédents— nous rappellent la puissance, mais aussi la faiblesse de nos typologies.
Leur faiblesse est due au fait qu’il est aisé de définir précisément une classe (par exemple les SE), mais pas l’autre: des SNE, nous savons juste qu’elles sont des « non-SE ». Autant la notion de comportement « moyen » ou « majoritaire » a du sens pour la catégorie définie de façon objective, autant elle n’en a pas dans l’autre 29. Et c’est clairement dans ce second groupe qu’on retrouvera le lot de pratiques variées (usages sophistiqués du vocabulaire et du moteur de recherche, etc.) qu’on a eu l’occasion de vérifier jusque là.
La force de notre méthode réside tout d’abord dans le fait qu’elle est itérative. Par exemple, on pourrait, au sein des SNE, définir précisément une sous-classe, puis le complémentaire de cette sous-classe, et ainsi de suite. Mais surtout, il nous apparaît que cette méthode est la seule possible. Au lieu de définir des « groupes » aux définitions vagues dans lesquels on insérera de force des comportements ou des personnes, pour respecter une idéologie ou pour obtenir coûte que coûte des phénomènes gaussiens, cette méthode par « dichotomies successives » semble être la seule qui respecte la structure statistique des objets que nous étudions. Puisque, parmi ceux-ci, ceux qui sont rares ont une grande importance, le seul moyen de les mettre en évidence consiste à les dégager, par une succession d’opérations, de la gangue des objets trop visibles qui les masquent.