|
|
Après la récolte de tant d’indices relatifs aux mots, requêtes, et sessions, nous pouvons maintenant opérer un regroupement des pratiques en fonction des « individus-cookies ». Un tel individu sera donc décrit par l’ensemble des sessions réalisées par un cookie particulier. Sa description sera nécessairement complexe 30, si l’on désire garder le maximum d’indicateurs pertinents relatifs à des « objets » qui s’emboîtent les uns dans les autres.
Chaque session est repérée par son type (SE ou SNE), son caractère (« simpliste » 31 ou pas), sa longueur, sa forme (répétition systématique ou pas), la taille de son lexique (nombre de mots distincts utilisés dans la session 32). La durée n’a pas été conservée puisqu’elle n’apparaissait pas pertinente.
Puis sont décrits les thèmes de chaque session en fonction des types de requêtes rencontrées: informatique spécifique (E comme informatique étroite), informatique au sens large (L pour large), pornographie (S comme sexe) et emploi (W pour work). Deux autres thèmes ont été ajoutés: anthropologie et sociologie 33 (G comme Goody), dictionnaire et traduction 34 (D comme dictionnaire). Une requête n’entrant dans aucune de ces rubriques était classifiée « autre » (A comme autre).
Ce travail a repris, en la généralisant, la méthode exposée au paragraphe 2.6 (cf. page 502); cependant, puisque nous travaillions sur plusieurs thèmes à la fois, il a fallu choisir un ordre pour classifier les requêtes: le programme commence par vérifier si une requête renvoie au thème G, puis E, puis D 35, puis W, puis L 36, et enfin S 37.
Enfin, les sessions sont regroupées par cookie.
À partir de la longueur et de la taille du lexique d’une session, nous déduisons des indicateurs dérivés: longueurs minimale, maximale et moyenne des sessions 38 des internautes; nombre de sessions de longueur 1, de longueur supérieure ou égale à 10; minimum et maximum des tailles de lexique des sessions de chaque personne.
Pour chaque personne, nous calculons enfin le nombre de requêtes d’un thème donné (A, D, E, etc.) dans l’ensemble de ses sessions.
Nous obtenons ainsi un fichier assez complexe, dont chaque ligne correspond à un internaute: on y retrouve son numéro de cookie, la description synthétique de chacune de ses sessions 39, et les indicateurs numériques initiaux et dérivés 40, dont la valeur maximale vaut dix (la valeur 10 signifie donc « dix ou plus »).
Les résultats précédents donnent à penser qu’une « personne-cookie » réalise en moyenne deux sessions dans la semaine 41. Dans les faits, 58 % des individus ainsi repérés ne font qu’une session, 20 % en font deux, 9 % trois, et donc 13 % quatre au plus.
La majorité des membres de notre panel utilise donc peu le moteur Goosta. Les taux trouvés sont conformes avec ceux que l’entreprise rencontre pour la totalité du portail qui héberge le moteur —et donc nécessairement plus consulté que le moteur lui-même: 42 % des « utilisateurs-cookies » réalisent une seule visite par semaine, 16 % en réalisent 2, 10 % 3. Ces faibles usages du moteur sont à mettre en regard des travaux de Valérie Beaudouin et de Houssem Assadi ([BA02]), qui montraient que les usagers à domicile consultaient un moteur de recherche 30 fois dans l’année en moyenne et donc, moins d’une fois par semaine 42. D’autres études ([BC01, Djo01]) rappellent la difficulté qu’ont les internautes à utiliser un moteur de recherche (mais n’offrent pas de réelles statistiques). Ainsi, même si nous reconnaissons les limites de notre échantillonnage —pour une étude plus poussée, il conviendrait de prendre une plage d’étude bien supérieure à la semaine, ce qui nécessiterait une machine autrement puissante—, nous espérons proposer une étude précise du comportement de ces 641 000 personnes.
Tout d’abord, nous évoquerons rapidement le cas des « profanes », ou nouveaux venus à l’internet. La constance de ces flux de néophytes expliquerait autant l’accroissement du nombre d’internautes que la lente évolution des usages de l’internet. Nous avons alors décidé de tester la pertinence de cet argument. Or, le cookie permet de connaître la première date de consultation du moteur par l’internaute. Il nous a permis de classer nos utilisateurs en trois groupes: personnes arrivées en mars 2001, en janvier ou février 2001, ou auparavant. On sait qu’un tel indicateur a deux biais: les personnes faisant une seule session de longueur 1 sont toutes venues sur Goosta au moins une fois avant mars (c’est ainsi qu’elles ont été repérées); inversement, parmi ces mêmes personnes ne réalisant qu’une session, mais de longueur supérieure à 2, les « nouvelles » sont légèrement sur-représentées, puisqu’elles intègrent les sessions avec refus de cookie que nous avons reconstituées. Les dates de première apparition du cookie sont assez bien distribuées: 39 % des personnes sont déjà venues sur Goosta avant 2001, 31 % en janvier ou février. Ceci dit, cette variable n’apporte pas d’informations probantes en matière de discrimation des pratiques. Il n’est donc pas sûr que les « anciens » aient des usages différents des nouveaux internautes qui découvrent Goosta.
La longueur moyenne des sessions vaut 1 pour 30 % des utilisateurs, 2 pour 24 % d’entre eux, 3 pour 14 % d’entre eux, et dépasse 5 pour 24 % d’entre eux. Il y a donc beaucoup de sessions courtes.
69 % des utilisateurs ont réalisé au moins une SE. Ceci montre l’intérêt d’une étude sur les personnes: elle met en évidence une forme de panachage des pratiques, puisqu’on ne rencontrait que 60 % de SE. De façon analogue, 65 % des personnes n’ont jamais fait de session avec répétition systématique, alors que 79 % des sessions étaient sans répétition (systématique). On peut vérifier cette combinaison d’usages en considérant le pourcentage d’auteurs de sessions de longueur un 43: il n’est que de 22 % quand on dénombrait 38 % de sessions de ce type; une minorité d’internautes réalise plusieurs sessions de longueur 1. En revanche, 14 % des utilisateurs ont réalisé au moins une session de longueur supérieure ou égale à 10, et 35 % une de longueur supérieure ou égale à 5 (23 % des sessions étaient de longueur supérieure ou égale à 5).
Nous n’en déduisons pas pour autant que les utilisateurs réguliers ne font que des sessions courtes: au contraire, le pourcentage des personnes réalisant au moins une session de longueur supérieure ou égale à 5 croît avec leur nombre de sessions, passant de 25 % chez les auteurs d’une session à 86 % pour ceux d’au moins dix.
Les auteurs de sessions « simplistes » forment, quant à eux, une catégorie assez homogène: ils sont 7797, soit quasiment autant que le total de ces sessions (8758).
|
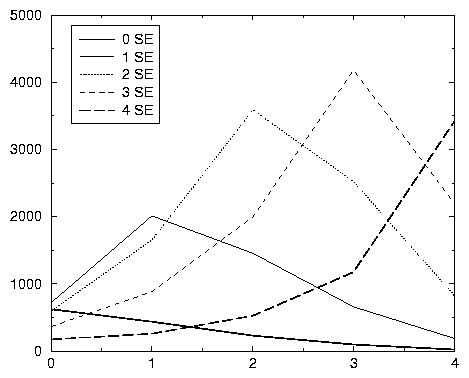
On pressent une corrélation entre l’émission de requêtes trop générales et cette forme d’abandon instantané du moteur. Pour la mettre en évidence, nous explicitons les relations entre les 4 variables suivantes: nombres de SE et de SNE, nombre de sessions de longueur 1, et (suite au travail précédent) nombre de sessions à répétition systématique. Cette évaluation est un peu délicate car les variables sont liées, mais non comparables quand le nombre de sessions varie 46.
Pour chaque tranche SE + SNE = k, on remarque que le nombre de sessions de longueur 1 et celui de sessions à répétition systématique croissent directement avec le nombre de SE.
À titre d’exemple, le tableau 3.6 donne les taux de sessions de longueur 1 rencontrés chez les personnes ayant fait 2, 3 ou 4 sessions. Nous savions déjà que le taux de sessions de longueur 1 croît avec le nombre de sessions. À nombre de sessions constant, le taux de sessions de longueur 1 croît avec le nombre de SE 47: ce taux de sessions de longueur 1 devient très important 48 pour les sessions à majorité SE (qui sont d’ailleurs de plus en plus majoritaires quand le nombre de sessions augmente).
|
|
|
|
Les résultats du tableau 3.8 montrent que, même parmi les personnes n’ayant réalisé qu’une session, dont les pratiques sont difficiles à commenter, 79 % des auteurs d’une SE ont un comb valant 1: environ 169 000 individus ont en fait réalisé une SE, de longueur 1, ou systématiquement répétée. Chez les auteurs de 4 SNE et d’aucune SE, 22 % d’entre eux ont un comb supérieur ou égal à 3. Ce pourcentage, pour les auteurs de 4 SE, se monte à 84 %.
|
Plus précisément, GR1 est défini comme suit: ce sont les personnes qui vérifient l’une ou l’autre des conditions suivantes:
— elles n’ont réalisé que des SE;
— leur nombre de SE est strictement supérieur à leur nombre de SNE et leur comb est égal à leur nombre de sessions.
Les personnes n’appartenant pas à GR1, qui ne vérifent donc aucune de ces deux contraintes, seront dénommées GR0 49.
La deuxième condition ne change pas considérablement le profil des 296 885 auteurs exclusifs de SE: elle ne leur ajoute que 5852 personnes. On a donc 47,2 % des utilisateurs qui entrent dans la catégorie GR1.
Il nous semblait essentiel de vérifier que notre définition était compatible avec nos indicateurs initiaux relatifs aux mots et requêtes. Le GR1 est co-responsable de la quasi totalité des requêtes courantes (il en manque 27 sur 10486); en termes de fréquence, cela fait 45,2 % de ces requêtes. Mais il n’est responsable que de 7,6 % des requêtes rares distinctes, dont le total vaut 880 792. En nombre d’occurrences, cela est équivalent: 7,7 %. Les mêmes calculs appliqués aux mots rares donnent des résultats analogues: 11,3 % du total des mots rares distincts, soit 9,9 % en poids. En revanche, le GR0 est bien responsable de la quasi-totalité des requêtes rares. De même pour les mots. Le tableau 3.9 récapitule l’ensemble de ces résultats.
|
79 % des auteurs GR1 d’une seule session ont un comb qui vaut un. Un comb égal au nombre de sessions apparaît chez 69 % des auteurs GR1 de deux sessions, chez 65 % des GR1 auteurs de trois sessions, etc. Pour l’autre groupe, les taux démarrent bien plus bas et chutent très vite: 27 % des auteurs d’une session, 19 % de ceux de deux, et moins de 5 % ensuite.
Ainsi, avons-nous mis en évidence un groupe spécifique, qui émet surtout des requêtes banales: les SE sont quasi-systématiques, et leur lexique est fort réduit. Dans une session, la reformulation d’une requête est rare. Le groupe GR1 semble donc particulièrement désarmé devant un moteur de recherche. Or ce groupe constitue la moitié de notre population.
Mais cela ne signifie pas pour autant que le GR0 soit composé de personnes expertes ès internet documentaire. En effet, ce second groupe est défini en négatif. Nous savons qu’il contient les personnes qui ont réalisé des sessions sophistiquées, mais aussi d’autres, qui en ont réalisé de bien plus communes (au vu du grand nombre de requêtes fréquentes qui apparaissent dans le tableau 3.9). Aussi ce constat nous invitera-t-il à prolonger l’entreprise de dichotomie itérative que nous avions évoquée à la fin du chapitre 3.1.6 (page 564).
De façon générale, le thème A (« autres » 51) est —par construction— largement majoritaire: 95 % des internautes l’ont évoqué dans au moins une requête. Sinon, le pourcentage de personnes s’étant intéressé à un thème donné est environ le double du taux de requêtes sur ce même thème 52.
Le taux d’internautes émettant des requêtes dictionnairiques semble faible (près d’1 %) mais n’est pas négligeable, puisque le lexique constituant le thème D n’est composé que de deux mots 53. Il en est de même pour le thème de l’écriture informatique et de la programmation (E): il n’était pas acquis qu’une personne sur cent sollicite des mots-clés aussi complexes et spécifiques. Par suite, le taux de personnes ayant rédigé au moins une fois rédigé une requête à connotation pornographique apparaît modéré (6,2 %), entre les préoccupations professionnelles (4,1 %) et l’informatique « grand public » (L), qui motive plus de 9 % des utilisateurs. Nous ne nous étonnons pas de la faible apparition du thème G, qui renvoie à toute la variété des préoccupations des internautes, mais il n’est pas désagréable d’apprendre qu’une personne sur 1500 s’intéresse à la sociologie et à l’anthropologie.
|
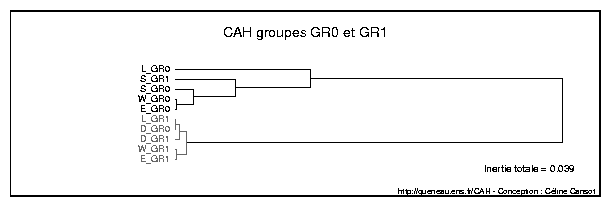
Un thème ne suit pas cette loi, celui de la pornographie: le rapport vaut 1. Et il est le seul où l’abandon est moins systématique pour le GR1 : comme le montre la classification 3.5, qui décrit le profil d’un thème (A exclu) en fonction du nombre de personnes l’ayant cité une fois, deux fois, etc. jusqu’à 10 fois ou plus, le GR1 apparaît homogène: les distances entre les thèmes (E_GR1, W_GR1, D_GR1 et L_GR1 ) sont faibles; mais le S_GR1 est présent au sein du profil GR0, nettement plus dispersé 54. L’idée n’est pas que les personnes les plus désemparées face à l’internet seraient des obsédés sexuels, mais que leur difficulté à trouver des réponses conformes à leurs réelles préoccupations les incite à n’utiliser les moteurs de recherche que dans un cadre ludique 55. Forme d’exclusion intellectuelle, violente entre toutes.
|
|
Nous pouvons maintenant prolonger notre démarche itérative.
Nous pourrions réaliser ces itérations de façon quasi-automatique. Mais le fait que certains des indicateurs soient fort synthétiques nous incitera à la prudence, ce qui nous permettra de prouver la fiabilité de notre méthodologie, et d’opérer quelques vérifications, qui garantiront que les indicateurs que nous avons choisis au fil de ce travail sont robustes.
Nous allons donc commencer par réduire légèrement GR0 et vérifier que les mots rares dans les deux nouveaux groupes obtenus se distribuent bien de la façon escomptée, puis étudier attentivement les auteurs d’une seule session, avant d’évaluer le taux de personnes familiarisées avec le fonctionnement des moteurs de recherche.
Nous décomposons le GR0 en deux sous-groupes: GR01, et son complémentaire GR00.
GR01 comprend les personnes dont:
— le comb est égal à leur nombre de sessions
ou dont
— au moins les trois-quarts (strictement) de leurs sessions sont des SE.
Ainsi, nous sélectionnons ici encore des individus aux requêtes banales, qui réalisent des sessions brèves ou sans reformulation. GR01 a donc un profil très proche de GR1.
La taille de GR01 n’est pas négligeable: 70 593 personnes, soit 21 % de GR0, responsables de 152 921 sessions 56. À eux deux, GR1 et GR01 réunissent 58,2 % des utilisateurs, et sont responsables de 17 % des requêtes rares distinctes 57. Si nous agrégeons ces deux groupes (dont la réunion est donc le complémentaire de GR00 ), les oppositions statistiques découvertes auparavant se maintiennent ou se renforcent; par exemple 76 % des personnes du groupe GR1 U GR01 ont un lexique maximum qui vaut 2, quand ce taux tombe à 5 % pour son complément GR00 (au lieu de 86 % face à 11 %).
Nous désirons d’abord vérifier la pertinence des critères de rareté, qui sont définis de façon statistique. Si quelques sondages attestaient de leur qualité, il reste néanmoins possible que des mots rares (ou des requêtes rares) soient en fait des mots banals dans lesquels se seraient glissées des fautes de frappe. Dans ce cas, la rareté ne serait pas synonyme de sophistication.
Aussi, parmi les mots rares rencontrés dans les requêtes émises par des personnes GR1 U GR01 , en avons-nous sélectionné un sur cent; de même pour GR00. Ce qui a donné respectivement 455 et 1982 mots. Ces mots ont été classifiés en quatre groupes: erreur en cas de faute de frappe manifeste (materiek, nostagie, etc.), doute s’il était difficile de garantir l’erreur (noms inconnus, comme lilootes, cedat, acopsante, ou ressemblant à des mots connus, comme auhan, ou maschio), web (URL plus ou moins complètes, mais sans faute de frappe, comme www.dad —mais www.education.gouvr.fr rentre dans la catégorie erreur, à cause du r de gouvr), et enfin autres, a priori corrects, comme lievremont, moho, narcotiques, presley, ou 110ch.
Dans chaque classe d’utilisateurs, le taux d’erreur est identique: un mot sur trois est mal écrit. En revanche, le taux de doute est plus élevé pour GR1 U GR01 que pour GR00 : 32,3 % contre 17 %. Il en est de même pour la catégorie web: 15,6 % contre 5,2 %. Au final, seul un mot rare sur cinq semble sans faute (ou susceptible d’exister dans un large dictionnaire) pour le groupe agrégé, face à un sur deux 58 pour GR00. Le tableau 3.11 synthétise ces résultats.
Aussi, les mots rares de GR1 U GR01 sont-ils fréquemment des mots susceptibles de n’être pas compris par le moteur, et on ne peut que se satisfaire de leur faible présence dans les requêtes de cette classe. A fortiori, si une personne de GR1 U GR01 saisit un mot rare, comme il y a 8 chances sur 10 pour que celui-ci soit incompris du moteur, sa réaction de rejet ou d’abandon risque d’être encore plus forte. Cela nous conforte dans l’idée que ce groupe GR1 U GR01 est particulièrement désarçonné par le fonctionnement des moteurs de recherche. À l’opposé, le fort taux de ces mots rares au sein de la classe complémentaire GR00, et le plus faible taux d’erreur prouvent que cette dernière émet effectivement des requêtes plus sophistiquées. Il est même possible de mesurer ce fait: une personne de GR00 a en moyenne 10 fois plus de chances 59 de saisir un mot rare correct qu’une personne de GR1 U GR01 .
|
Le type de critère utilisé a effectivement une incidence sur les agrégations
construites, mais celle-ci est limitée: pour montrer ce fait, considérons par exemple
GR00, que nous scindons en deux groupes; CL1 est défini par les critères
suivants:
— le nombre de SE est strictement supérieur au nombre de SNE
ou
— le lexique maximal est inférieur ou égal à 3.
CL0 est son complémentaire. CL1 réalise bien les sessions les plus communes 60.
Ici, deux personnes qui ont le même profil, mais dont l’une réalise deux sessions quand l’autre en réalise trois, ne seront pas classées dans le même sous-groupe 61.
|
|
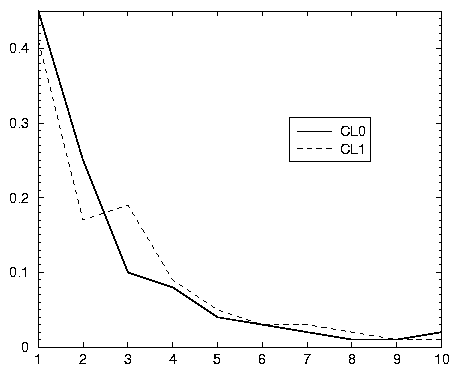
Le graphique 3.6, montre que les deux sous-groupes ont une fréquentation analogue du moteur, ce qui est déjà une information riche en soi. Cependant, nous constatons des différences quand le nombre de sessions vaut deux ou trois: c’est bien là que le critère employé induit une rupture. Mais si l’on fait la somme, pour CL0 comme pour CL1, des auteurs de 2 ou 3 sessions, ces brutales variations s’annulent: 35 % au total pour les CL0, 36 % pour les CL1. D’autre part, ces biais, qui se compensent, donc, ne s’étendent pas quand le nombre de sessions dépasse le seuil choisi: à partir de 4 sessions, les résultats sont identiques pour les deux groupes.
Ainsi, les critères employés sont susceptibles d’introduire des biais aux abords du seuil choisi à la marge, mais ces biais sont peu importants.
Nous savons que les personnes mal à l’aise consultent peu le moteur, quand les autres le font plus fréquemment 62. Cependant, il n’est pas impossible que des utilisateurs familiers des moteurs se glissent parmi la population des personnes qui consultent rarement Goosta. Par exemple, les « experts » habitués à utiliser plusieurs moteurs à la fois; il serait alors erroné de prétendre que le nombre de sessions d’une personne est en relation directe avec ses capacités documentaires sur l’internet. Aussi, pour mesurer le taux de personnes disposant d’une compétence certaine, devons-nous distinguer les auteurs d’une et de plusieurs sessions.
Mais les 31 % d’autres personnes n’étant venues qu’une fois ont —par construction, puisqu’ils sont dans GR00 — un comportement différent des GR1 U GR01 : pour tous, la longueur de la session vaut au moins 2, et elle dépasse (au sens large) 5 dans 48 % des cas. Tous sollicitent un lexique de taille supérieure ou égale à 2. De plus, 42 % d’entre eux (48 911 personnes, soit 13 % des GR00 n’ayant réalisé qu’une session) ont un lexique 64 de taille supérieure ou égale à 5. Un tel seuil semble témoigner d’une capacité certaine des utilisateurs à tirer parti d’un moteur de recherche.
Ces 48 911 personnes sont auteurs de 126 932 requêtes rares distinctes, quand les 67 921 autres (toujours GR00 auteurs d’une seule session) ont émis 87 037 autres requêtes rares distinctes (en sus, 1452 sont communes aux deux sous-groupes). L’étude de quelques sessions réalisées par les personnes utilisant un lexique consistant donne à penser que leurs requêtes sont variées, reformulées, et efficaces 65.
Nous pouvons donc en déduire que 13 % des personnes utilisant rarement Goosta (venues une fois seulement dans notre fenêtre temporelle) sont certainement familières des moteurs de recherche. Nous découvrons une classe d’usagers compétents, mais volatiles, qui ont un comportement en rupture complète avec la grande majorité des autres visiteurs épisodiques, pour lesquels nous avons dû constituer des discriminations du plus bas niveau possible afin de repérer un minimum de maîtrise du moteur.
Parmi ces auteurs d’au moins deux sessions, presque la moitié (44 %) sont dans le groupe GR1 U GR01. Nous doutons que les 150 723 personnes restantes —de GR00, donc— soient toutes familiarisées avec l’informatique et les requêtes sur l’internet: en effet, 97 243 de ces personnes ont émis au moins une session de longueur 1. Un sondage rapide sur ces sessions de longueur 1, comme sur celles dont le lexique ne contient qu’un mot, montre qu’elles sont souvent très simples et peu évocatrices (« anpe », par exemple).
Sinon, 45 % de ces 150 723 personnes ont réalisé une session de longueur supérieure ou égale à 4. 59 % d’entre elles ont un lexmax supérieur ou égal à 5, ce qui commence à être important. Mais seulement 9 % ont un lexmin supérieur ou égal à 4, et 4 % un lexmin supérieur ou égal à 5.
Sachant que nous ne pouvons appliquer un critère aussi simple que précédemment, puisqu’ici, nos auteurs de multiples sessions peuvent alterner requêtes banales et complexes, nous nous proposons d’utiliser une fois de plus les indicateurs habituels pour opérer une coupure au sein de ce groupe de personnes venues au moins deux fois dans la semaine, et semblant un minimum familiarisées avec les moteurs de recherche. Nous regroupons d’une part les personnes remplissant l’une des conditions suivantes (groupe GR001), d’autre part son complémentaire 66 (dénommé GR000):
— le nombre de SE est supérieur ou égal au nombre de SNE;
— les sessions de longueur 1 composent au moins la moitié du total des sessions;
— le lexique minimum d’une session vaut 1 (il existe donc au moins une session composée d’un seul mot);
— le lexique maximal des sessions ne dépasse pas 3;
— la longueur moyenne des sessions vaut 1.
GR001 est bien plus important que GR000: 115 885 personnes, responsables de 430 362 sessions, quand GR000 ne représente que 34 838 personnes (pour 114 370 sessions). Nous remarquons que GR000 a de fortes chances d’intégrer les personnes dont le lexmax est supérieur ou égal à 4.
Bien sûr, les deux groupes émettent de nombreuses requêtes rares: 542 539 à eux deux, dont 7307 communes à GR001 et à GR000. Mais chaque personne de GR000 est responsable d’environ 5,5 requêtes rares distinctes en moyenne, quand ce taux tombe à 3,1 pour GR001. Inversement, et toujours « en moyenne », une personne de GR001 est responsable de 4,8 requêtes fréquentes 67, et une personne de GR000 de 3,6. Enfin, les sessions des GR000 sont en moyenne de longueur 5. En matière de thèmes, les taux de GR000 sont plus élevés que pour la moyenne, ce qui est en partie logique, puisque qu’ils réalisent plusieurs sessions: 1,3 % d’entre eux ont émis des requêtes de type D, 9,7 % de type S et 8,2 % de type W. Les plus fortes augmentations se retrouvent pour les thèmes E (2,4 %), G (0,2 %) et L (18,2 %). Ce dernier pourcentage prouve que les personnes qui maîtrisent l’internet ont conscience du besoin de continuer à se cultiver dans le domaine de l’informatique.
Au vu de ces résultats, nous sommes conduit à penser que c’est parmi ces 34 838 personnes —soit 13 % des auteurs d’au moins deux sessions— que nous retrouverons les internautes disposant d’une maîtrise minimale de l’outillage intellectuel contemporain.
Il faudrait vérifier ce résultat, avec des études approfondies, incluant des enquêtes ethnographiques, mais d’ores et déjà, les témoignages d’étudiants, évoquant leurs collègues, professeurs, amis et parents, nous donnent à penser qu’il est juste, même s’il déplaît.
Notre raisonnement est le suivant: pour aller dans le sens des analyses que nous comptons critiquer, et pour réduire le poids des fautes de frappe, nous ne considérons que les requêtes fréquentes ou communes apparues dans les 3 mois, tous utilisateurs confondus. Nous sommes donc assuré que la fréquence totale de ces requêtes est supérieure à 20. Nous comptons combien de fois les membres de GR000 saisissent ces requêtes, puis comparons le rang général d’une requête avec celui qu’elle a dans GR000.
Pour à la fois expliciter cette méthode et montrer en quoi les variations sont faibles pour les requêtes majoritaires, le tableau 3.12 donne les fréquences et rangs respectifs des requêtes qui sont les dix premières dans GR000 ou dans le total.
|
Afin d’éviter une trop forte influence de l’échantillonnage sur le résultat, nous ne considérons que les requêtes fréquentes ou communes dont la fréquence dans GR000 est inférieure à la moitié de la fréquence dans le corpus entier 69. Les résultats pour limite = 5, sont présentés dans l’annexe (tableaux 4.1 page 724 et 4.2 page 728).
Bien sûr, toutes les requêtes composées d’un mot simple, polysémique quand il est seul, voient leurs rangs s’accroître grandement: ainsi, les requêtes très vagues —mais trop faciles à interpréter?— comme « impot », « race », « parisien », « loto », « sexy », « loterie », « erotique », « pmu », « anal », etc., ont des rangs entre 1000 et 5000 dans GR000 quand ce rang initial était compris entre 20 et 600. Et d’autres, comme « barcelone », « golf » ou « gif anime », se retrouvent au rang 11 000 alors qu’ils semblaient « importants », si l’on en croit leurs rangs initiaux: respectivement 737, 398, 647.
Inversement, des requêtes bien plus pertinentes se retrouvent dans les premiers rangs: « fievre aphteuse » (rang 11 au lieu de 419), « geographie » (124 au lieu de 764), « seine maritime » (149 au lieu de 12 667), « louis 16 » (307 au lieu de 13 775), « ubu roi » (433 au lieu de 19 749), « egalite homme femme » (593 au lieu de 34 871), « declaration droit homme citoyen » (679 au lieu de 20 403), « elections communales » (877 au lieu de 45 389), « phlebologie » (1642 au lieu de 54 448).
Ces quelques exemples convaincront assurément le lecteur que les représentations d’autrui les plus primaires, aisées à réaliser si on effectue une lecture rapide et non raisonnée des rangs et fréquences des requêtes, s’effondrent lorsqu’on s’intéresse aux utilisateurs ayant un minimum de pratique des moteurs. Les préoccupations culturelles, géographiques et politiques des internautes apparaissent alors bien plus clairement.